本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1jG-rGG4QMuZu0t0kEEl7SA?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/Data_Visualization直方图通过将数据划分为多个区间(bin),统计每个区间内数据的出现次数(频数),并用矩形的高度表示频数大小。它与条形图的关键区别在于:直方图用于展示连续数据的分布,区间之间无间隙;而条形图用于展示离散类别数据,类别之间相互独立。
函数语法:
plt.hist(x, bins=None, *, range=None, density=False,weights=None, cumulative=False, bottom=None,histtype='bar', align='mid', orientation='vertical',rwidth=None, log=False, color=None, label=None,stacked=False, data=None, **kwargs)
-
x:输入数据,必须是可迭代的数组或数组列表。
-
bins:直方图的柱子数量或边界值。可以是整数(指定柱子数量)、序列(明确指定柱子的边界)、字符串(如 'auto'、'sturges'等)。 -
range:数据范围,格式为 (min, max)。超出范围的值会被忽略。若未指定,默认为 (x.min(), x.max())。 -
density:是否将直方图的总和归一化为1。若为 True,直方图面积为 1(概率密度);若为 False(默认),显示频数。 -
weights:每个数据点的权重,形状需与 x 相同,用于调整统计计算(如加权直方图)。如果density是True,则权重被归一化,默认是False。 -
cumulative:布尔值。若为 True,绘制累积分布直方图(频数或密度的累计值)。 -
bottom:柱子的基线位置(默认为 0)。可用于堆叠直方图的偏移。 -
histtype:直方图类型,字符串类型。取值包括,'bar'(默认,传统柱状图)、'barstacked'(堆叠柱状图)、'step'(无填充的线条直方图)、'stepfilled'(有填充的线条直方图)。 -
align :柱子对齐方式,字符串类型。取值包括,'mid'(默认,柱子居中于刻度)、'left' 或 'right'(左对齐或右对齐)。 -
orientation:方向。取值包括,'vertical'或 'horizontal'。 -
rwidth:柱子的相对宽度(0~1),控制柱子之间的间隙,浮点数类型。若为 None,自动调整。 -
log:布尔值,若为 True,y 轴使用对数刻度。 -
color:柱子颜色,支持颜色名称(如 'red')、十六进制码或 RGB 元组。 -
label:图例标签,需配合 plt.legend() 使用。 -
stacked:布尔值,若为True,多组数据堆叠显示。 -
data:允许从字典或 DataFrame 中提取数据(如 data=df, x='column_name')。 -
**kwargs:传递给 matplotlib.patches.Polygon 的属性,如 edgecolor、linewidth、alpha、hatch 等,进一步美化柱形。
通过调整这些参数,可以灵活控制直方图的视觉效果。
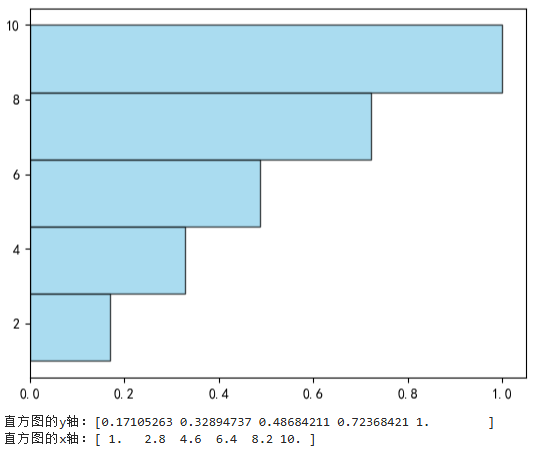
# 生成随机数据
np.random.seed(1)
data = np.random.randint(1,15,size=100)
# 绘制直方图
h = plt.hist(data,
range=(1,10), # 数据范围,超出范围的值会被忽略
bins = 5, # 指定柱子数量
density=True, # 显示频率而非计数
cumulative=True, # 绘制累积分布直方图
align='mid', # 调整柱子边缘对齐
color='skyblue', # 柱子颜色
edgecolor='black', # 边框颜色
alpha=0.7, # 透明度(0-1)
orientation='horizontal'# 水平方向
)
plt.show()
# 打印函数回传值
# 列表类型,列表第0个元素是y轴的值,即x轴值的频率值或计数值
# 列表第1个元素是x轴的各bin分割点的坐标值
print(f"直方图的y轴:{h[0]}")
print(f"直方图的x轴:{h[1]}")
可视化结果如下图所示:
使用示例:
-
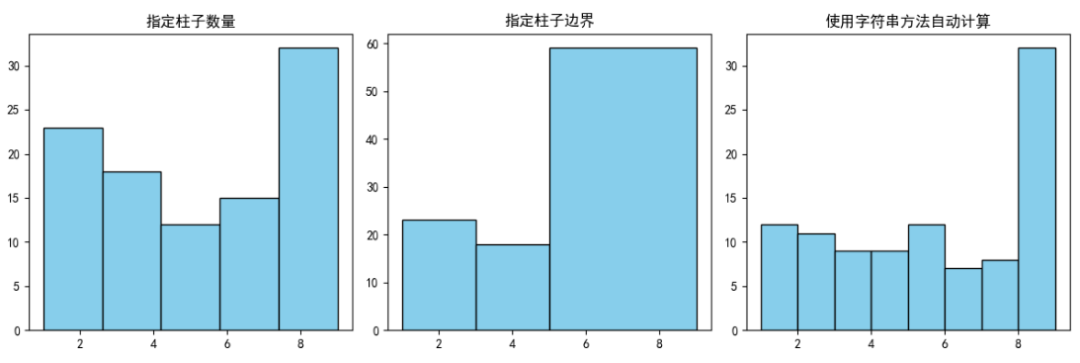
2.1 bins参数:
在直方图中,bins参数定义了如何将数据范围划分成连续的区间(箱子),并统计每个区间内数据点的频数或频率。bins参数非常灵活,主要有以下几种设置方式:
-
整数:直接指定区间数量,Matplotlib 会自动将数据范围均分。
-
序列:直接指定每个区间的边界值,如 bins=[0, 5, 10, 15]。这种方式可以创建不等宽的区间,适用于有明确业务划分需求的场景(如年龄、成绩分档等)。
-
字符串:使用特定算法自动计算合适的区间数量。Matplotlib支持多种自动计算bins数量的算法(如'auto', 'fd', 'scott', 'sqrt'等),这些算法基于数据特性智能选择最佳区间数量。
# 生成随机数据
np.random.seed(1)
data = np.random.randint(1,10,size=100)
plt.figure(figsize=(12, 4))
plt.subplot(131)
plt.hist(data, bins=5,color='skyblue',edgecolor='black')
plt.title('指定柱子数量')
plt.subplot(132)
plt.hist(data, bins=[1,3,5,9],color='skyblue',edgecolor='black')
plt.title('指定柱子边界')
plt.subplot(133)
# 其他选项: 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges', 'sqrt'
plt.hist(data, bins='sturges',color='skyblue',edgecolor='black')
plt.title('使用字符串方法自动计算')
plt.tight_layout()
plt.show()
-
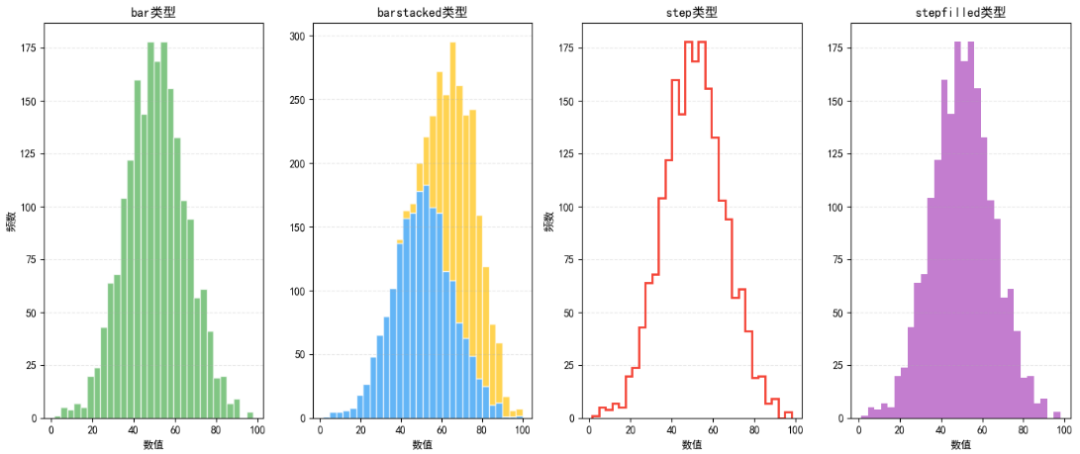
2.2 histtype参数:
在直方图中,histtype参数用于控制直方图的呈现样式,取值包括以下四种类型,每种类型有其独特的视觉效果和适用场景。
-
'bar':标准柱状直方图,每个区间以独立柱子呈现,多组数据时并列显示。适用于单组数据的分布展示、多组数据的横向对比。 -
'barstacked':多组数据堆叠显示,每组数据的柱子叠加在另一组上方,体现整体与部分的关系。适用于展示多组数据的累计分布, -
'step':仅显示直方图的轮廓线,不填充颜色,线条呈阶梯状。适用于需要弱化柱子形态、强调分布趋势的场景。 -
'stepfilled':在'step'的基础上增加填充色,兼具轮廓线和面积感。适用于既需要展示分布形状,又希望通过填充色突出数据区域的场景。
# 生成示例数据
np.random.seed(42)
data = np.random.normal(50, 15, 2000) # 正态分布数据
data = data[(data >= 0) & (data <= 100)] # 过滤合理范围外的值
# 创建画布
plt.figure(figsize=(14, 6))
# 1. bar类型(默认)
plt.subplot(141)
plt.hist(data, bins=30, histtype='bar', color='#4CAF50', edgecolor='white', alpha=0.7)
plt.title('bar类型', fontsize=12)
plt.xlabel('数值', fontsize=10)
plt.ylabel('频数', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.3)
# 2. barstacked类型(添加第二组数据展示堆叠效果)
plt.subplot(142)
data2 = np.random.normal(70, 10, 1500)
data2 = data2[(data2 >= 0) & (data2 <= 100)]
plt.hist([data, data2], bins=30, histtype='barstacked',
color=['#2196F3', '#FFC107'], edgecolor='white', alpha=0.7)
plt.title('barstacked类型', fontsize=12) # 修正标题错误
plt.xlabel('数值', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.3)
# 3. step类型
plt.subplot(143)
plt.hist(data, bins=30, histtype='step', color='#F44336', linewidth=2)
plt.title('step类型', fontsize=12) # 修正标题错误
plt.xlabel('数值', fontsize=10)
plt.ylabel('频数', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.3)
# 4. stepfilled类型
plt.subplot(144)
plt.hist(data, bins=30, histtype='stepfilled', color='#9C27B0', alpha=0.6)
plt.title('stepfilled类型', fontsize=12)
plt.xlabel('数值', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.3)
# 调整布局
plt.tight_layout()
plt.show()
-
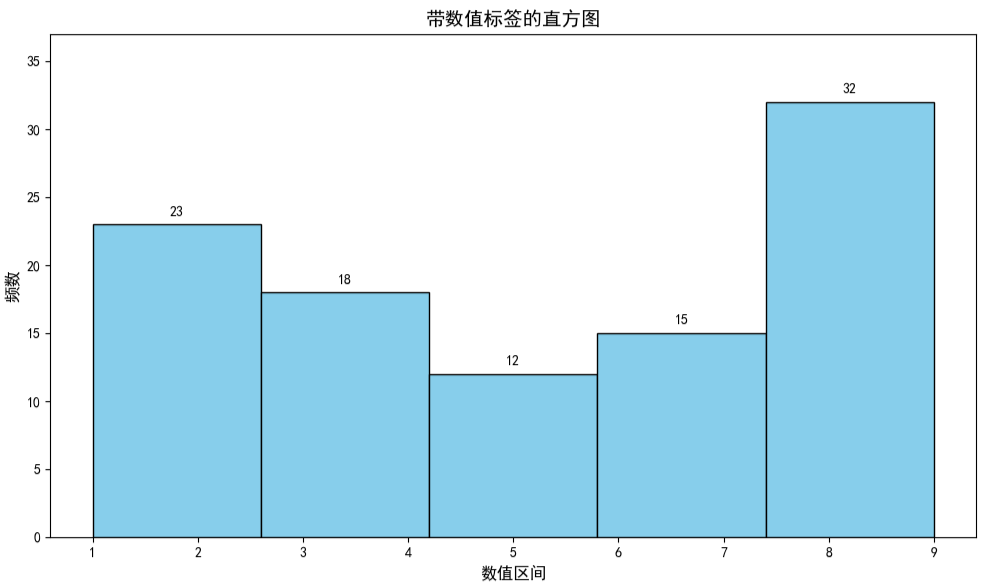
2.3 添加统计信息标注:
为直方图添加数值标签的核心是利用hist()函数的返回值定位每个柱形,并通过plt.text()添加文本标签。
hist()函数调用后会返回一个包含三个元素的元组(n, bins, patches),这三个返回值分别对应直方图的频数数组(或密度数组)、区间边界数组、图形对象列表,合理使用它们可以帮助我们更灵活地处理和定制直方图。
-
n:频数数组(或密度数组)
-
bins:区间边界数组
-
patches:图形对象列表
# 生成随机数据
np.random.seed(1)
data = np.random.randint(1, 10, size=100)
# 绘制直方图
plt.figure(figsize=(10, 6))
n, bins, patches = plt.hist(data, bins=5, color='skyblue', edgecolor='black')
# 添加数值标签
for i in range(len(patches)):
# 获取每个矩形的高度(频数)
height = n[i]
# 在矩形上方居中位置添加标签
plt.text(
patches[i].get_x() + patches[i].get_width() / 2, # x坐标(矩形中心)
height + 0.5, # y坐标(矩形顶部+少量偏移)
f'{int(height)}', # 标签文本(频数,转换为整数)
ha='center', # 水平居中
va='bottom', # 垂直底部对齐
fontsize=10
)
# 添加标题和坐标轴标签
plt.title('带数值标签的直方图', fontsize=14)
plt.xlabel('数值区间', fontsize=12)
plt.ylabel('频数', fontsize=12)
# 设置y轴范围,留出标签空间
plt.ylim(0, max(n) + 5)
plt.tight_layout()
plt.show()
-
2.4 堆叠与分组显示:
在 Matplotlib 中,堆叠显示与分组显示直方图是对比多组数据分布的两种常用方式。
-
堆叠显示直方图
通过设置stacked=True参数实现,特点是多组数据在同一区间内堆叠呈现:
# 生成两组数据
np.random.seed(1)
data1 = np.random.normal(0, 1, 1000)
data2 = np.random.normal(3, 1.5, 1000)
# 堆叠显示
plt.hist([data1, data2], bins=30, stacked=True,alpha=0.5,label=["data1","data2"])
plt.legend()
plt.title('堆叠显示直方图', fontsize=14)
plt.show()
可视化结果如下图所示:
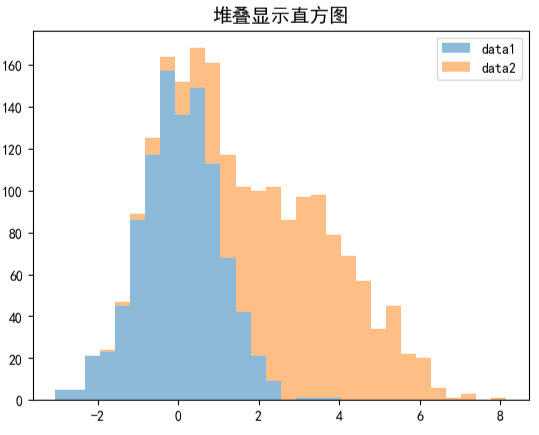
-
分组显示直方图
通过默认参数(或显式设置histtype='bar')实现,特点是多组数据在同一区间内并列呈现。
# 生成两组数据
np.random.seed(1)
data1 = np.random.normal(0, 1, 1000)
data2 = np.random.normal(3, 1.5, 1000)
# 堆叠显示
plt.hist([data1, data2], bins=30,alpha=0.5,label=["data1","data2"], histtype='bar')
plt.legend()
plt.title('分组显示直方图', fontsize=14)
plt.show()
可视化结果如下图所示:
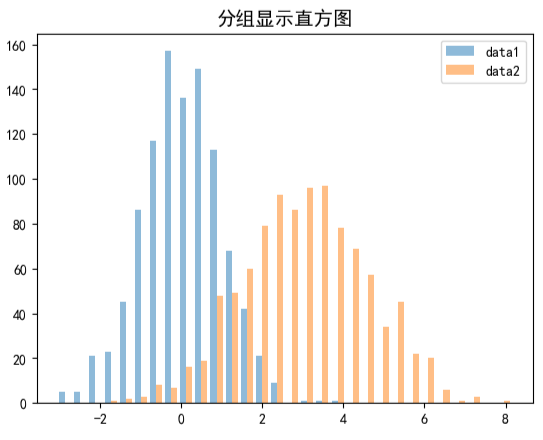
-
2.5 组合图(叠加核密度估计KDE):
直方图叠加核密度估计这种组合方式结合了直方图的实际数据分布展示和 KDE 曲线的平滑分布趋势刻画,能更全面地呈现数据特征:直方图保留原始数据的分布细节,KDE 曲线则通过平滑处理突出整体分布形态(如是否为单峰 / 双峰分布、偏斜程度等)。
from scipy.stats import gaussian_kde
# 通过拼接两个正态分布数据创建了一个双峰分布数据集
np.random.seed(1)
data = np.concatenate([np.random.normal(0, 1, 500),
np.random.normal(5, 1, 500)])
# 绘制直方图
plt.hist(data, bins=50, density=True, alpha=0.5, color='gray')
# 添加KDE曲线
# 用scipy.stats.gaussian_kde()计算数据的核密度估计,得到密度函数density
density = gaussian_kde(data)
# 生成 x 轴取值范围(如np.linspace(-3, 8, 200)),覆盖数据的合理区间
xs = np.linspace(-3, 8, 200)
# 通过plt.plot(xs, density(xs))绘制核密度曲线,设置颜色(如'r-'红色实线)和线宽(如2)突出显示
plt.plot(xs, density(xs), 'r-', linewidth=2)
plt.title('组合图(叠加核密度估计KDE)')
plt.show()
可视化结果如下图所示:
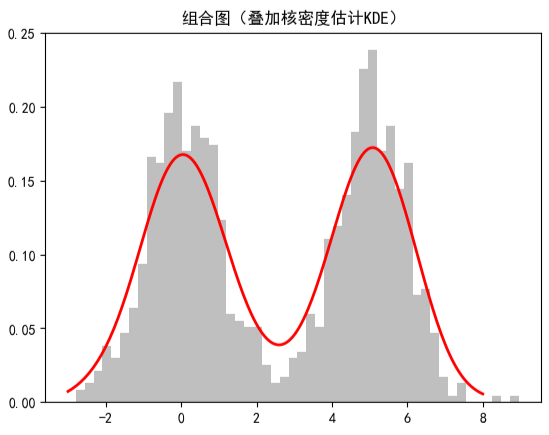
更多内容可以前往官网查看:
https://matplotlib.org/stable/


本篇文章来源于微信公众号: 码农设计师
{kind=link}