本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
-----------------------------------------------------
最通用的 GroupBy 方法是 apply,这是本节的主题。apply将被操作的对象拆分为多个部分,对每个部分调用传递的函数,然后尝试将其拼接起来。
之前介绍的 agg 方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量。
apply 是一个更一般化的方法:将一个数据分拆-应用-联合。而apply会将当前分组后的数据一起传入,可以返回多维数据。
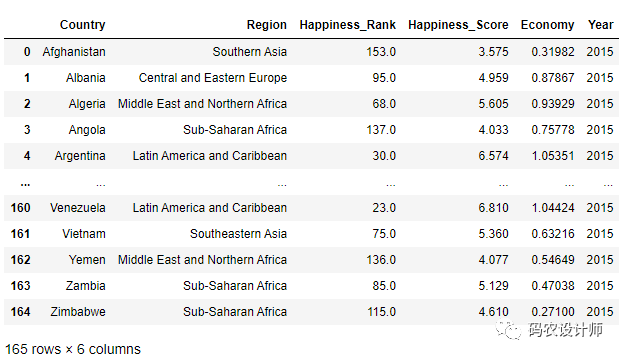
本次以全球幸福指数数据为例:
1>>> df = pd.read_csv("./data/happiness_report.csv")
2>>> df
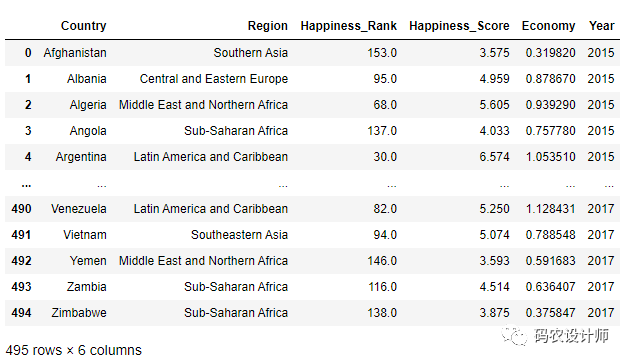
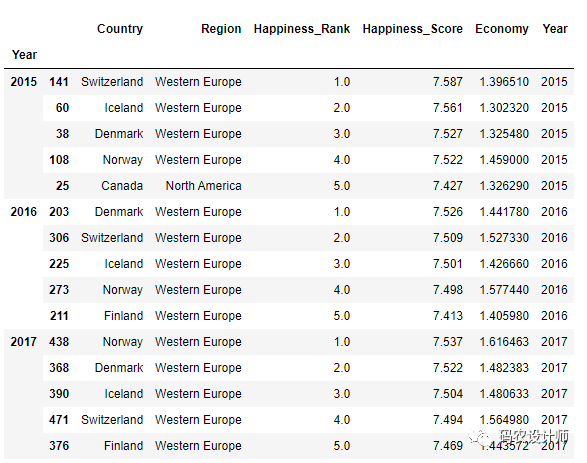
然后,按Year分组,再调用 apply方法。
1>>> def top(df,n=5,column="Happiness_Score"):
2... return df.sort_values(column , ascending=False)[:n]
3
4>>> df.groupby("Year").apply(top)
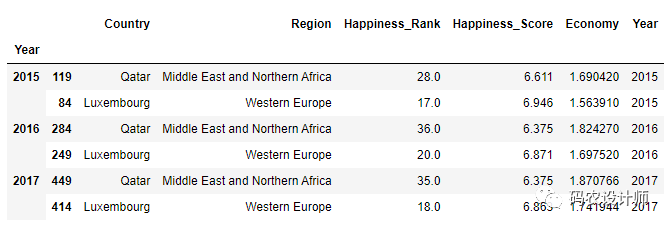
除了可以向 apply 传递函数,也可以传递其他参数或关键字。
1>>> df.groupby("Year").apply(top , n=2 , column="Economy")
除了这些基本的使用机制之外,充分利用 apply 可能需要一些创造力。传递的函数内部发生的事情由你决定;它只需要返回一个 pandas 对象或一个标量值。
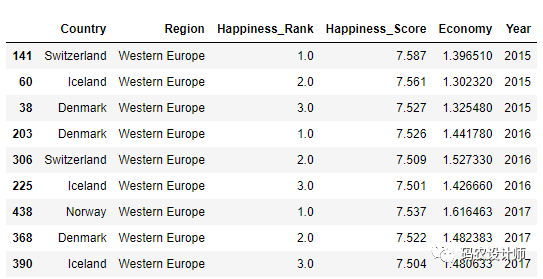
在前面的示例中,你会看到生成的对象具有一个由分组键形成的分层索引,以及每个原始DataFrame 对象的索引。你可以通过将 group_keys=False 传递给 groupby 来禁用此功能。
需要注意的是,group_keys与as_index的功能类似但是也存在一些区别。as_index在限制显示分组键时会以数字序号替代,但group_keys则是不将分组键作为索引,只显示之前的行索引。
1>>> df.groupby("Year" ,group_keys=False).apply(top, n=3 )
本小节以上述数据中的2015年的数据为例:
1>>> df_2015 = df[df["Year"]==2015]
2>>> df_2015
Pandas有一些工具,尤其是pandas.cut 和 pandas.qcut,用于将数据按照你选择的箱位或样本分位数进行分桶。与groupby 方法一起使用这些函数可以对数据集更方便地进行分桶或分位分析。
本次根据Economy列进行分桶操作。
1>>> quartiles = pd.cut(df_2015["Economy"] , 4)
2>>> quartiles
30 (-0.00187, 0.468]
41 (0.468, 0.935]
52 (0.935, 1.403]
63 (0.468, 0.935]
74 (0.935, 1.403]
8 ...
9490 (0.935, 1.403]
10491 (0.468, 0.935]
11492 (0.468, 0.935]
12493 (0.468, 0.935]
13494 (-0.00187, 0.468]
14Name: Economy, Length: 495, dtype: category
15Categories (4, interval[float64, right]): [(-0.00187, 0.468] < (0.468, 0.935] < (0.935, 1.403] < (1.403, 1.871]]
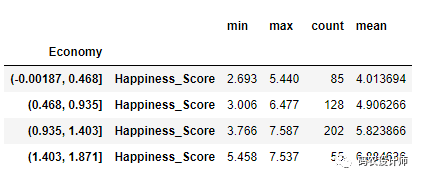
pandas.cut 返回的Categorical对象可以直接传递给groupby,所以我们可以计算出一组四分位数的分组统计数据。
1>>> def get_stats(group):
2... return pd.DataFrame({
3... "min": group.min(),
4... "max": group.max(),
5... "count": group.count(),
6... "mean": group.mean()})
7
8>>> grouped = df_2015.groupby(quartiles)
9>>> grouped[["Happiness_Score"]].apply(get_stats)
可以通过 agg 更简单地计算相同的结果。
1>>> grouped[["Happiness_Score"]].agg(["min", "max", "count", "mean"])
1>>> quartiles_samp = pd.qcut(df_2015["Economy"] , 4, labels=False)
2>>> quartiles_samp
30 0.0
41 1.0
52 1.0
63 1.0
74 2.0
8 ...
9490 2.0
10491 1.0
11492 0.0
12493 1.0
13494 0.0
14Name: Economy, Length: 495, dtype: float64
15
16
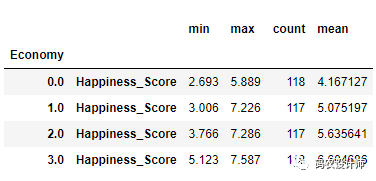
17>>> grouped = df_2015.groupby(quartiles_samp)
18>>> grouped[["Happiness_Score"]].apply(get_stats)
本篇文章来源于微信公众号: 码农设计师
{kind=link}