Python受欢迎的原因之一就是其计算生态丰富,据不完全统计,Python 目前为止有约13万+的第三方库。
本系列将会陆续整理分享一些有趣、有用的第三方库。
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1FSGLd7aI_UQlCQuovVHc_Q?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/Python_Ecosystempip install tablibpip install "tablib[all]"
# 等价于
pip install "tablib[html, pandas, ods, xls, xlsx, yaml]"
https://github.com/jazzband/tablib-
创建数据集:
import tablib
# 创建一个空的数据集
data = tablib.Dataset()
# 通过 Dataset.headers 添加表头
headers = ('Name', 'Country')
data.headers = headers
# 通过 Dataset.append 添加数据行
data.append(['Alice', 'USA'])
data.append(['Bob', 'Canada'])
# 通过 Dataset.append_col 添加数据行
data.append_col([25, 39], header='Age')
print(data)
# 输出:
# Name |Country|Age
# -----|-------|---
# Alice|USA |25
# Bob |Canada |39
# 通过 Dataset.dict 获取数据集的 Pythonic 视图
data.dict
# 输出:[{'Name': 'Alice', 'Country': 'USA', 'Age': 25},
# {'Name': 'Bob', 'Country': 'Canada', 'Age': 39}]
-
数据导入:
tablib 支持从多种格式的文件中导入数据,tablib 会检测传入的数据类型,并使用适当的格式来进行导入。 因此,可以从各种不同的文件类型中导入数据。
以下是从 CSV 文件导入数据的示例:
import tablib
# 从 CSV 文件导入数据
with open('data.csv', 'r') as fh:
imported_data = tablib.Dataset().load(fh, format='csv', headers=False)
print(imported_data)
# 输出:姓名|年龄|性别
# 张三|25|男
# 杨慧|28|女
-
数据导出:
# 逗号分隔值(CSV)
print(data.export('csv'))
# JavaScript 对象表示法(JSON)
print(data.export('json'))
# YAML(YAML 不是标记语言)
print(data.export('yaml'))
# Microsoft Excel
print(data.export('xls'))
# Pandas DataFrame
print(data.export('df'))
-
数据操作:
-
选择行和列:
# 切片:第一行
data[0]
# 切片:前两行
data[0:2]
# 索引直接访问某一行
data.get(0)
# 查看列名
# data.headers
# 通过列名获取某列值
data['Name']
# 通过索引访问列
data.get_col(1)
# 简单计算
ages = data['Age']
float(sum(ages)) / len(ages)
-
删除行和列:
# 删除一列
del data['Age']
# 删除一系列行
del data[0:2]
-
动态列:
动态列是一个可调用对象(例如一个函数)。当添加一个动态列时,传递给可调用对象的第一个参数是当前数据行,可以利用它对数据行进行计算。
例如,我们可以使用行中的数据来返回性别。
# 定义函数
def guess_gender(row):
"""根据name计算性别。"""
m_names = ('Bob', 'Mike', 'Yuri')
f_names = ('Alice', 'Samantha', 'Heather')
# 获取第一列
name = row[0]
if name in m_names:
return'Male'
elif name in f_names:
return'Female'
else:
return'Unknown'
# 将函数作为动态列添加到数据集中
data.append_col(guess_gender, header='Gender')
# 查看数据
data.export('df')
# 输出: Name Country Age Gender
# 0 Alice USA 25 Female
# 1 Bob Canada 39 Male
-
使用标签过滤数据集:
在构建 Dataset 对象时,可以通过指定 tags 参数为行添加标签,这样就为行添加了额外的元数据,后续可以轻松地过滤 Dataset。
students = tablib.Dataset()
students.headers = ['first', 'last']
# 在构建 Dataset 对象时,通过 tags 参数为行添加标签
students.rpush(['Kenneth', 'Reitz'], tags=['male', 'technical'])
students.rpush(['Daniel', 'Dupont'], tags=['male', 'creative'])
students.rpush(['Bessie', 'Monke'], tags=['female', 'creative'])
# 使用标签过滤数据集
print(students.filter(['female']).dict)
# 输出:[{'first': 'Bessie', 'last': 'Monke'}]
# 默认情况下,当你传递一个标签列表时,你会得到“或”类型的过滤结果。
print(students.filter(['female', 'creative']).dict)
# 输出:[{'first': 'Daniel', 'last': 'Dupont'}, {'first': 'Bessie', 'last': 'Monke'}]
# 通过链式调用,你可以得到“与”类型的过滤结果
print(students.filter(['female']).filter(['creative']).dict)
# 输出:[{'first': 'Bessie', 'last': 'Monke'}]
-
操作Excel:
-
打开 Excel 工作簿并读取第一个工作表:
打开一个 Excel 2007 或更高版本的工作簿,其中包含一个工作表(或者是一个包含多个工作表的工作簿,但只想读取第一个工作表)。
data = tablib.Dataset()
with open('data.xlsx', 'rb') as fh:
data.load(fh, 'xlsx')
print(data.dict)
# 输出:[{'姓名': '张三', '年龄': 25, '性别': '男'}, {'姓名': '杨慧', '年龄': 28, '性别': '女'}]
-
带有多个工作表的 Excel 工作簿:
在处理大量表格格式的数据集(Datasets)将多个电子表格组合到一个 Excel 文件(工作簿,Workbook)中是一种常见操作。tablib 库提供了非常方便的 Databook 类来实现这一功能。
具体来说,假如我们有 3 个不同的 Dataset 对象,只需要将它们添加到一个 Databook 对象中,tablib 就能帮助我们把这些数据集整合到一个 Excel 工作簿里,每个数据集对应工作簿中的一个工作表(Sheet)。
import tablib
# 创建第一个数据集
headers1 = ('Name', 'Age')
data1 = tablib.Dataset(headers=headers1)
data1.append(('Alice', 25))
data1.append(('Bob', 30))
# 创建第二个数据集
headers2 = ('Fruit', 'Quantity')
data2 = tablib.Dataset(headers=headers2)
data2.append(('Apple', 10))
data2.append(('Banana', 15))
# 创建第三个数据集
headers3 = ('City', 'Population')
data3 = tablib.Dataset(headers=headers3)
data3.append(('New York', 8000000))
data3.append(('Los Angeles', 4000000))
# 创建 Databook 对象
databook = tablib.Databook()
# 将数据集添加到 Databook 中
# 可以为每个数据集指定工作表的名称
databook.add_sheet(data1)
databook.add_sheet(data2)
databook.add_sheet(data3)
# 也可以使用下面的方式
# book = tablib.Databook((data1, data2, data3))
# 将 Databook 导出为 Excel 文件
with open('multi_sheet_workbook.xlsx', 'wb') as f:
f.write(databook.export('xlsx'))
print("Excel 文件已生成:multi_sheet_workbook.xlsx")
-
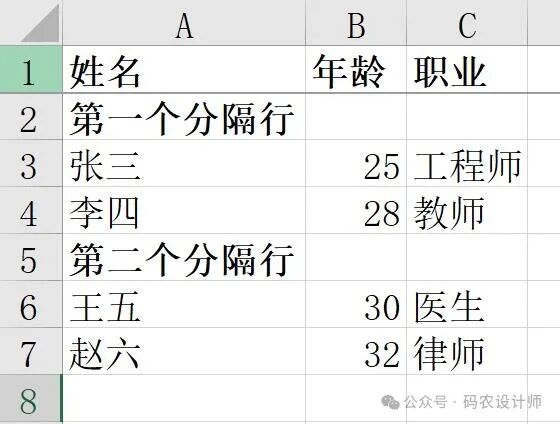
分隔符:
在构建电子表格时,创建一个空白行用于包含即将显示的数据信息通常很有用。
在 tablib 库中,append_separator 方法用于在 Dataset 中添加一个分隔行,分隔行通常用于视觉上分隔不同的数据组。
需要注意的是,目前只有 Excel 输出支持分隔符。
import tablib
# 创建一个数据集并设置表头
headers = ('姓名', '年龄', '职业')
data = tablib.Dataset(headers=headers)
# 添加分隔行
data.append_separator('第一个分隔行')
# 添加第一组数据
data.append(('张三', 25, '工程师'))
data.append(('李四', 28, '教师'))
# 添加分隔行
data.append_separator('第二个分隔行')
# 添加第二组数据
data.append(('王五', 30, '医生'))
data.append(('赵六', 32, '律师'))
# 将电子表格写入磁盘
with open('output.xlsx', 'wb') as f:
f.write(data.export('xlsx'))
保存的excel文件如下:
更多内容可以前往官方文档查看:
https://tablib.readthedocs.io/en/stable/

本篇文章来源于微信公众号: 码农设计师
{kind=link}