在数据分析中,Excel是最常见的数据来源之一。本文将介绍SPSS读取Excel文件(.xlsx / .xls)的操作步骤。
一、操作步骤
以下步骤适用于Excel 95及更高版本的文件。
步骤一:读取文件
- 菜单操作:点击顶部菜单栏 【文件→打开→数据】(在「文件类型」下拉框中选择Excel格式)或者【文件→导入数据→Excel】,在弹出窗口中,选择Excel 文件(支持 .xls 和 .xlsx)。
- 直接拖拽:直接将现有的Excel文件拖放到已打开的SPSS窗口中,SPSS会自动弹出同样的设置对话框,后续操作一致。
步骤二:导入设置
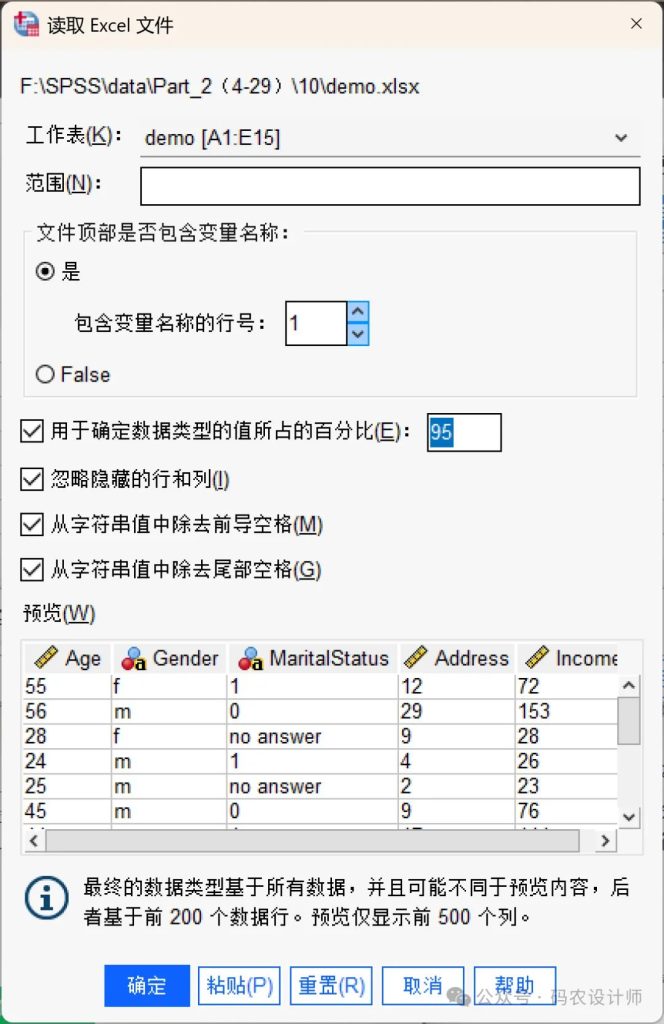
在打开的【读取Excel文件】对话框进行相应设置:
| 选项 | 含义 |
| 工作表 | Excel文件可能包含多个工作表。默认情况下,数据编辑器会读取第一个工作表。如需读取其他工作表,可从下拉列表中选择相应的工作表。 |
| 范围 | 可使用与Excel中相同的语法来指定单元格范围(如A1:F10)读取特定的单元格区域。 |
| 文件顶部是否包含变量名称 | 可以从文件的第一行或所定义的第一行读取变量名。不符合变量命名规则的值将被转换为有效的变量名,而原始名称将被用作变量标签。例如,示例Excel数据中的【Marital Status】列名中的空格会被删除。选择「是」:需指定包含变量名的行号(默认值为1),该行号之前的行将被忽略。例如,如果设置「包含变量名的行号」为4,则第 1、2、3行将被忽略,第4行的值将被设置为变量名,并从第5行开始读取数据。选择「否」:如果文件的第一行中没有添加变量名,勾选该选项,此时系统会为数据分配一组默认的变量名。 |
| 用于确定数据类型的值所占的百分比 | 在导入数据时,SPSS 需要判断每一列(字段)应被识别为数值型还是字符串型。由于某些列可能包含混合内容(例如部分单元格为数字,部分为文本),SPSS 会通过抽样检查一定比例的观测值(行)来推断该列的数据类型。此选项用于设定 SPSS 在自动判断变量类型时所需检查的最小有效值比例,该比例必须大于 50%。需要注意的是:如果在指定比例的非空值中,无法找到一种统一的数据格式,则该变量将被默认设为字符串类型;若变量根据该比例被判定为数值型(包括日期、时间等格式),则后续不符合该格式的值将被自动转换为系统缺失值。 |
| 忽略隐藏的行和列 | 勾选后,导入时将跳过Excel文件中被隐藏的行和列。该选项仅适用于Excel 2007及更高版本的文件(XLSX, XLSM)。 |
| 从字符串值中除去前导/尾部空格 | 勾选后,导入时会自动去掉字符串开头/结尾的空格。例如,示例数据中【Gender】列中部分值以空格开头,勾选后将会删除空格。 |
上述任何操作效果均会在对话框中的【预览】栏显示,可以根据显示效果查看设置是否正确。
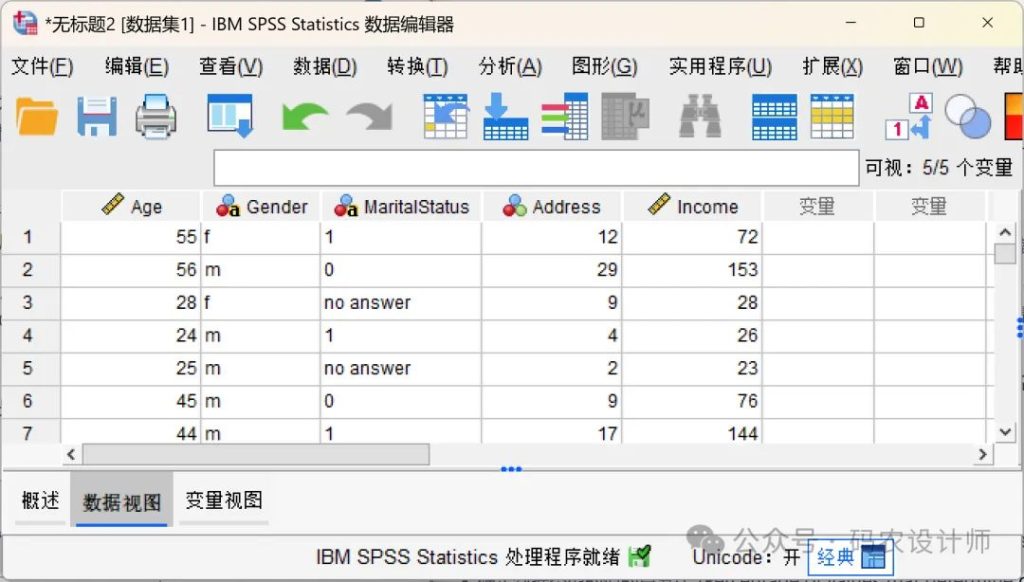
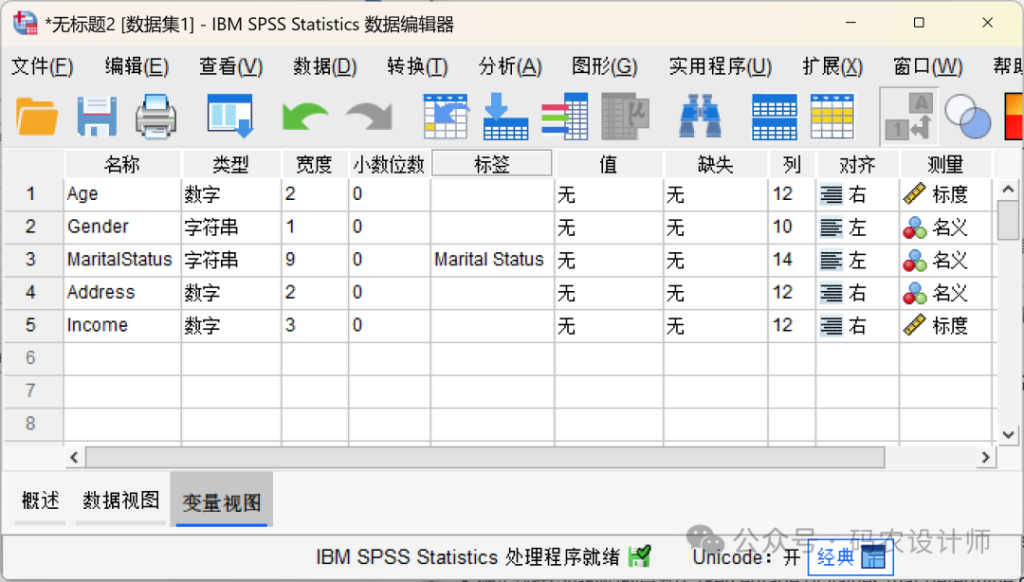
点击确定,SPSS就会根据设置将Excel文件读入数据编辑器。在「变量视图」中可以看到,示例Excel数据中的列名「Marital Status」因包含空格,不符合 SPSS 的变量命名规则,系统会自动将其转换为合法的变量名(MaritalStatus),同时将原始带空格的名称保留为该变量的标签。
导入完成后,建议仔细检查导入结果,包括变量名是否正确、数据是否完整、变量类型是否恰当等,以确保数据准确无误地载入。
确认数据导入无误后,点击菜单栏「文件→保存」,将数据保存为「.sav」格式(SPSS默认格式)。日后如需再次使用,只需双击该.sav文件即可直接打开,无需重复导入Excel数据。