打开SPSS软件后,默认弹出的就是「数据编辑窗口」,不管是新建数据文件,还是打开已有的数据源。
该窗口是用户输入、查看和管理数据的主要界面。它看起来像 Excel 表格,但功能更专业,专为统计分析设计。
该窗口包含以下三个标签页(选项卡):
- 概述(Overview)
- 数据视图(Overview)
- 变量视图(Variable View)
其中,概述选项卡为较新版本(SPSS 29+)新增。
一、概述(Overview)
概述标签页提供了对整体数据集和具体变量的全面信息,分为上下两个部分:
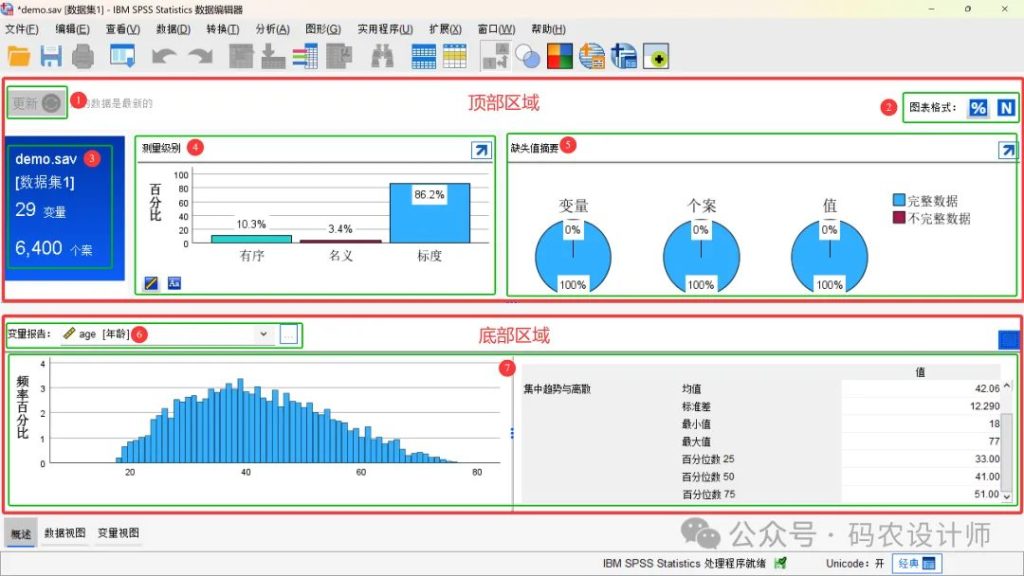
顶部区域:数据集概要
| 序号 | 功能选项 | 含义 |
| 1 | 更新按钮 | 位于左上角。当数据集或文件内容发生更改时,该按钮将自动启用。点击后可刷新视图,确保显示内容与最新数据保持同步。 |
| 2 | 图表格式切换按钮 | 位于右上角,用于切换当前选项卡中所有图表的两种显示模式(计数、百分比)。 |
| 3 | 信息卡片 | 显示当前数据集名称、关联文件名,以及变量总数和个案数量。 |
| 4 | 变量信息区域 | 该区域用于展示数据集中变量的结构特征:可以查看变量类型的频数分布,或按已分配的测量级别(如名义、有序、尺度)进行分类统计。图表左下角两个切换按钮,用于在「变量类型」和「测量级别」视图之间进行切换。点击右上角的箭头按钮,可直接跳转至「变量视图」,进行更详细的变量设置与管理。 |
| 5 | 缺失值汇总 | 以直观的饼图形式呈现变量、个案及单个数据值的完整性情况,分别展示完整数据与缺失数据的比例。若系统加载「缺失值」模块,则会显示一个箭头按钮,点击后将打开「多重插补:分析模式」对话框,便于进一步处理缺失数据。 |
底部区域:选定变量详情
| 选项 | 功能选项 | 含义 |
| 6 | 变量报告 | 通过下拉菜单选择特定变量进行深入查看。点击右侧的「...」按钮可以打开「选择变量」对话框,在弹出的对话框中,可以通过以下方式筛选变量:按已分配的测量级别(如名义、有序或尺度)进行过滤;在搜索框中输入关键词进行查找。搜索内容将匹配变量名称。若变量标签已启用显示,则同时匹配名称和标签。 |
| 7 | 变量详情图表 | 对于分类变量(即测量级别为「名义或有序」,且唯一取值不超过100个): 左侧将显示条形图或饼图,呈现各唯一值的频数或百分比;右侧将列出对应的频数表,包含唯一值、出现次数及其占比。点击箭头按钮可打开「频数」对话框,进行更详细的频率分析。对于尺度变量:左侧将显示直方图,纵轴可通过「图表格式切换按钮」切换为频数或百分比;右侧将提供一组描述性统计量,包括均值、标准差、最小值、最大值,以及第25、50(中位数)和75百分位数。点击箭头按钮将打开「探索」对话框,进行更全面的数据分布分析。 |
二、数据视图(Data View)
数据视图是用户与原始数据直接互动的窗口,呈现为类似Excel的表格形式,核心功能是录入、修改、查看数据。
核心结构:
- 每一行代表一个个案(Case),比如一个受访者、一次实验记录;
- 每一列代表一个变量(Variable),比如性别、年龄、成绩等。
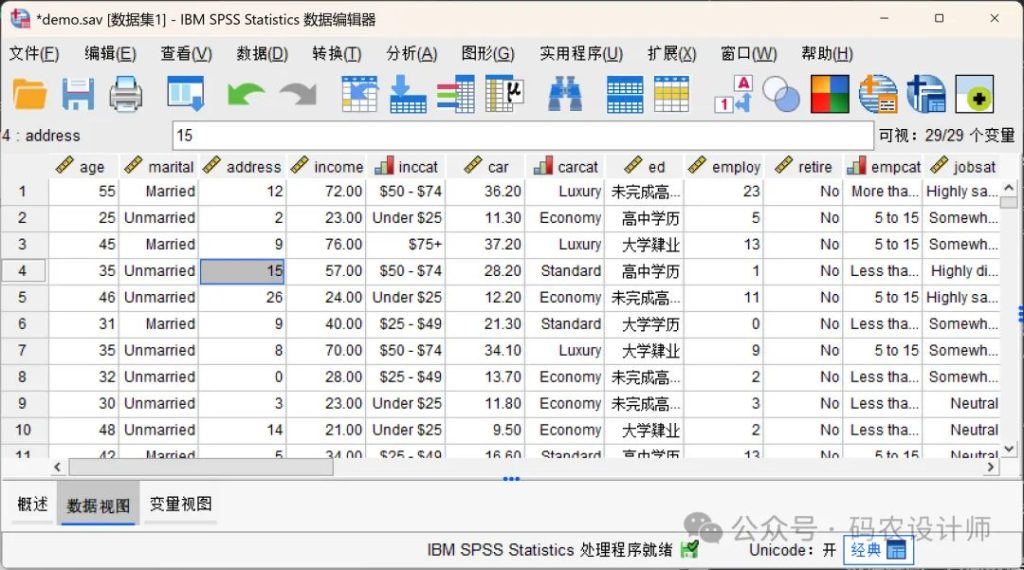
操作要点:
- 直接编辑:点击单元格即可输入或修改数据值;
- 数据验证:输入时会自动检查是否符合「变量视图」中设定的规则;
- 直观呈现:显示的是数据的具体「值(Value)」,而非编码或标签(变量视图中设置);
- 及时保存:SPSS不会自动保存数据修改,需手动保存,避免数据丢失。
注意事项:
在数据视图中录入数据时需遵循「变量视图」的预设规则。
例如,如果在变量视图里已经设定「性别」是「1=男,2=女」,那么在数据视图的「性别」列,就只能填「1/2」,不能填「男/女或3/4」,否则SPSS会提示无效数据(显示为红色)。同理,「年龄」若设定为整数,就不能填18.5,只能填18或19。
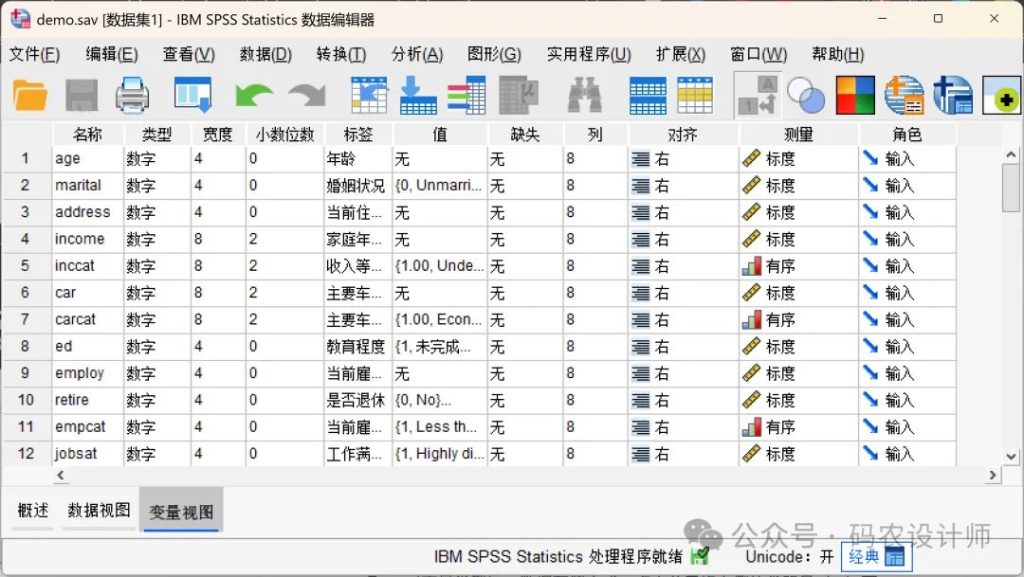
三、变量视图(Variable View)
变量视图是SPSS区别于普通电子表格软件的核心设计,通过精确控制每个变量的属性,为后续统计分析奠定基础。
点击数据编辑窗口左下角「变量视图」选项卡,会看到一个有11列的表格,每一列对应该变量的一种属性设置:
名称:
变量唯一标识符,变量名必须唯一且不超过64个字符。可以使用字母、数字和下划线,不能包含空格和特殊字符。
命名要简洁、有逻辑,避免后续分析时混淆。建议使用简洁英文或拼音命名(如 gender、age、score_total),后续可以通过「标签」列进行补充说明。
类型(变量类型):
数据存储方式。点击单元格右侧的省略号(…)可打开类型选择器,根据需要选择变量类型(数值型、字符串型、日期型等)。
需要注意的是,要根据数据本质而非表现形式选择类型(如身份证号虽为数字,但应设为字符串型)。
宽度:
变量可存储的最大字符长度。
小数位数:
数值型变量小数位数。
标签:
变量详细说明(可含空格)。输出结果会优先显示标签,而非简写的变量名。例如,变量「Score」的标签可以设为「问卷调查总得分(满分100)」,这样在输出分析结果时,显示的就是易懂的标签,而非简略的名称,极大提升可读性。
值:
定义分类变量的编码对应关系,即给分类变量的数值添加文字说明。例如,性别变量(1 =男,2 = 女)、Likert量表(1 = 非常不同意,5 = 非常同意)。
缺失(缺失值设置):
定义无效数据标识,可选择无缺失值(默认选项,适合数据完整的情况)、离散缺失值(手动输入无效数值,比如999,SPSS会自动识别为缺失值)或范围缺失值(设置一个范围,比如年龄>120,超出范围的数值会被识别为缺失值)。SPSS会自动在计算均值、方差时忽略这些值。
列(显示宽度):
数据可容纳的字符数,只是可视化宽度,不影响数据本身。
对齐:
数据对齐方式,包括,左对齐、中间对齐、右对齐,仅影响视觉效果,对分析无影响。
测量:
变量测量尺度。测量尺度的正确选择直接决定后续可采用的统计方法,务必根据变量的实际测量水平审慎设定。包含以下三个选项:
①、标度(Scale):变量的取值代表带有有效量度标准的有序类别,且取值间的距离比较具备实际意义。如年龄、身高、收入。适用于t检验、方差分析、回归等。
②、有序(Ordinal):等级型数据,可排序但差值无意义。如满意度评级(1-5级)、教育程度(小学<初中<高中<大学)。适用于非参数检验(如 Mann-Whitney U)等。
③、名义(Nominal):分类数据,无顺序与数量关系。如性别、职业、地区等。适用于卡方检验、交叉表等。
需要注意的是,对于字符串型有序变量,系统会默认其字符取值的字母顺序为类别的实际排序。例如,某字符型变量的取值为low、medium、high时,系统会将类别顺序解读为high、low、medium,这与实际正确的排序不符。一般情况下,使用数字编码(通过值列定义)表示有序型数据会更可靠。
角色(变量角色):
主要用于建模分析(如回归、决策树)时指定变量用途。常见角色包括,Input(输入)、Target(目标)、Both、None 等。初学者可暂时忽略,默认为 Input 即可。
关于变量视图中各变量属性更为详细的介绍可以查看官方文档:
https://www.ibm.com/docs/zh/spss-statistics/31.0.0?topic=editor-variable-view