文本文件是常见的数据来源之一。许多电子表格软件和数据库系统都可以将数据导出为不同类型的文本格式,常见的包括以下两类:
- 分隔符文本文件:该类文件使用特定符号将各列数据分开,常见的分隔符有,逗号(CSV 格式)、制表符(Tab)、分号以及空格等。
- 固定宽度文本文件:该类文件不依赖分隔符,而是通过字符所在的“位置”来区分不同字段。也就是说,每一列数据占据固定的字符宽度,各变量由列号范围来确定。
一、操作步骤
步骤一:读取文件
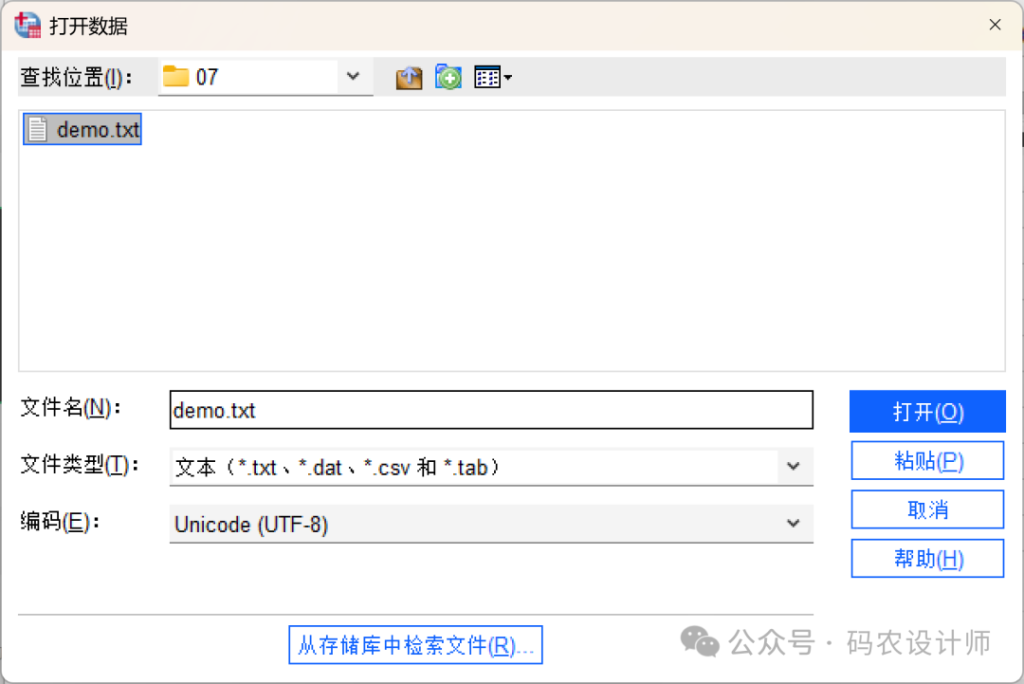
- 菜单操作:点击顶部菜单栏 【文件→打开→数据】(在「文件类型」下拉框中选择文本格式)或者【文件→导入数据→文本数据】,在弹出窗口中,选择文本文件(支持.txt、.csv、.dat、.tab格式)。
- 直接拖拽:直接将现有的Excel文件拖放到已打开的SPSS窗口中,SPSS会自动弹出同样的设置对话框,后续操作一致。
默认文件编码为「Unicode (UTF-8)」,如有需要可以在此选择正确的编码,避免乱码。
步骤二:文本向导
点击打开,SPSS会启动文本导入向导,用于定义读取数据文件的方式。
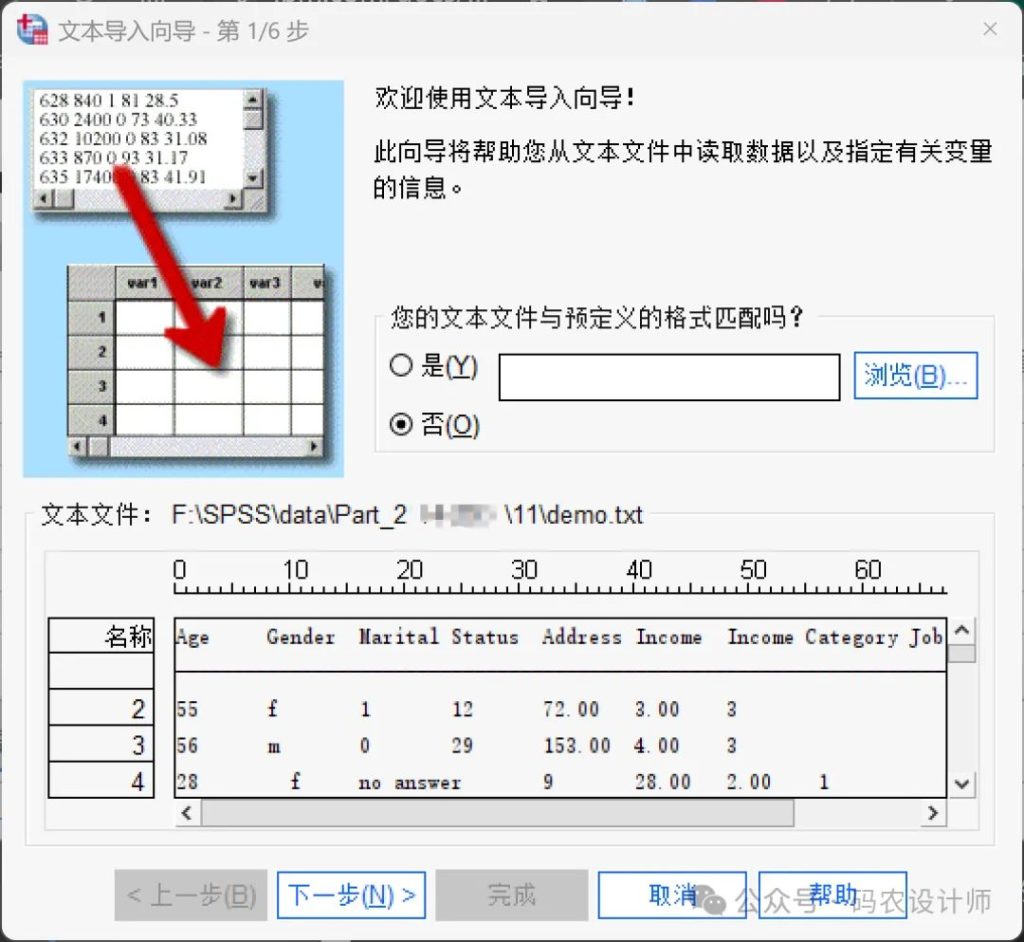
- 第1步:
此时要导入的文本文件将显示在预览窗口中。
可以应用预定义格式(此前通过文本向导保存的格式),或按照文本向导的步骤来指定数据的读取方式。
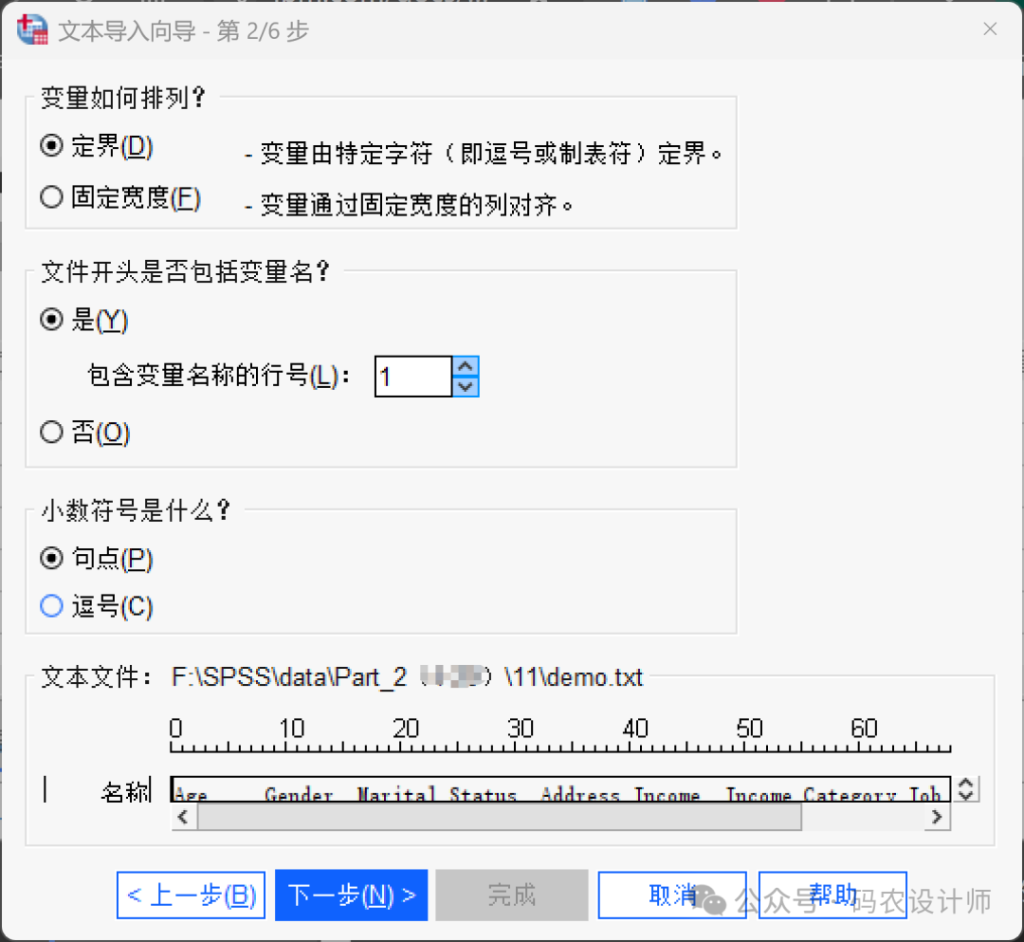
- 第2步:
该步骤用于设置变量相关信息。
| 选项 | 含义 |
| 变量如何排列 | 变量的排列方式决定了区分不同变量的方法:定界:使用空格、逗号、制表符或其他字符来分隔变量。对于每个个案,变量均按相同顺序记录,但不一定位于相同的列位置。固定宽度:对于数据文件中的每个个案,每个变量均记录在同一列位置的同一记录(行)上。变量之间不需要分隔符,列位置决定了正在读取的是哪个变量。需要注意的是,文本向导无法读取固定宽度的Unicode文本文件。如需读取此类文件,可使用DATA LIST命令。 |
| 文件开头是否包含变量名 | 指定行号上的值将被用作变量名。不符合变量命名规则的值将被自动转换为有效的变量名。 |
| 小数符号 | 用于表示小数值的字符可以是句点(.)或逗号(,)。 |
本次示例文件采用制表符分隔格式,即定界排列方式。第一行为列名,且小数点为句点(.)。
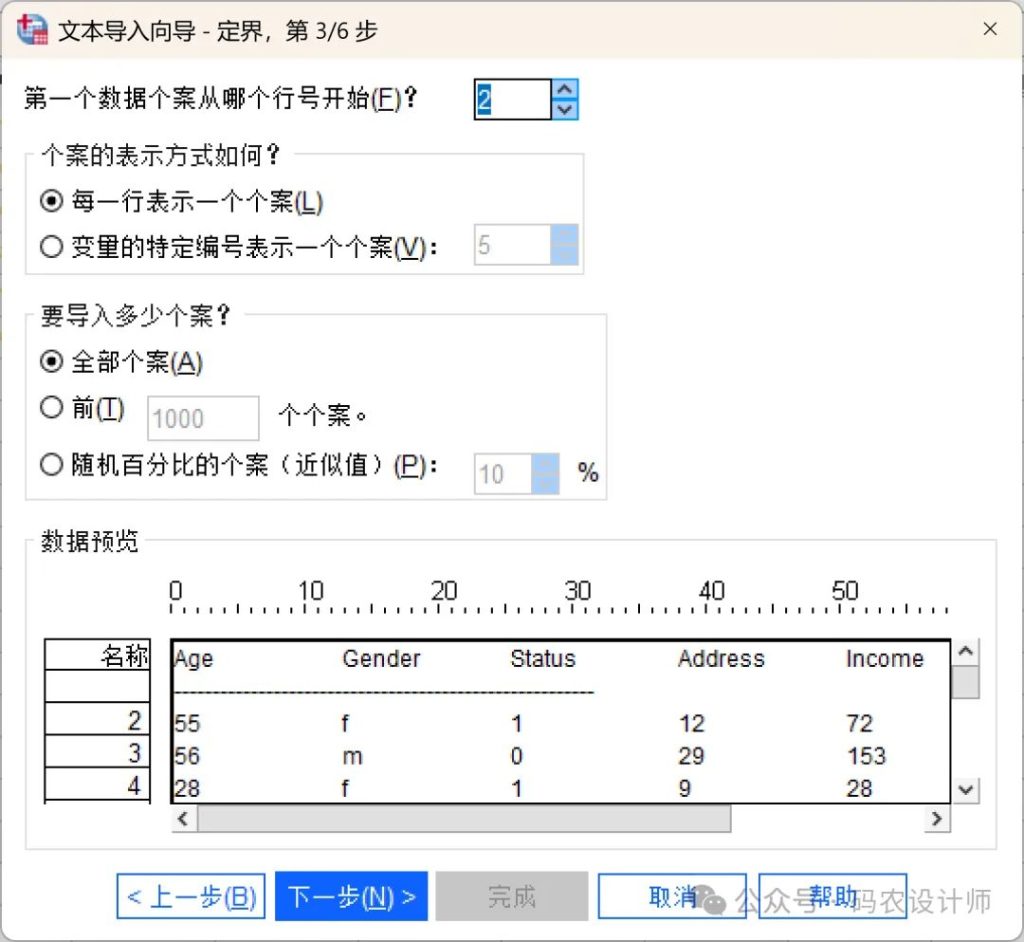
- 第3步:
该步骤用于设置个案相关信息。
| 选项 | 含义 |
| 第一个数据个案从哪个行号开始 | 指定包含数据值的数据文件第一行。 |
| 个案的表示方式 | 控制文本向导确定每个个案结束位置以及下一个个案开始位置的方式:每行代表一个个案:每行仅包含一个个案。如果并非所有行都包含相同数量的数据值,则每个个案的变量数将由包含数据值最多的那一行决定。对于数据值较少的个案,其额外的变量将被分配一个缺失值。特定数量的变量代表一个个案:为每个个案指定的变量数量,告诉文本向导在哪里停止读取当前个案并开始读取下一个个案。同一样本可以包含多个个案,个案也可以从某一行的中间开始并延续到下一行。文本向导根据读取的值的数量确定每个个案的结束位置,而与行数无关。每个个案必须包含所有变量的数据值(或由分隔符表示的缺失值),否则数据文件将无法被正确读取。 |
| 要导入多少个案 | 选择导入数据文件中的所有个案、前n个个案,或指定百分比的随机样本。由于随机抽样会对每个个案做出独立的伪随机决定,因此所选个案的百分比只能近似于指定的百分比。数据文件中的个案越多,所选个案的百分比就越接近指定的百分比。 |
本次示例文件第一行是变量名,所以数据从第2行开始。
- 第4步:
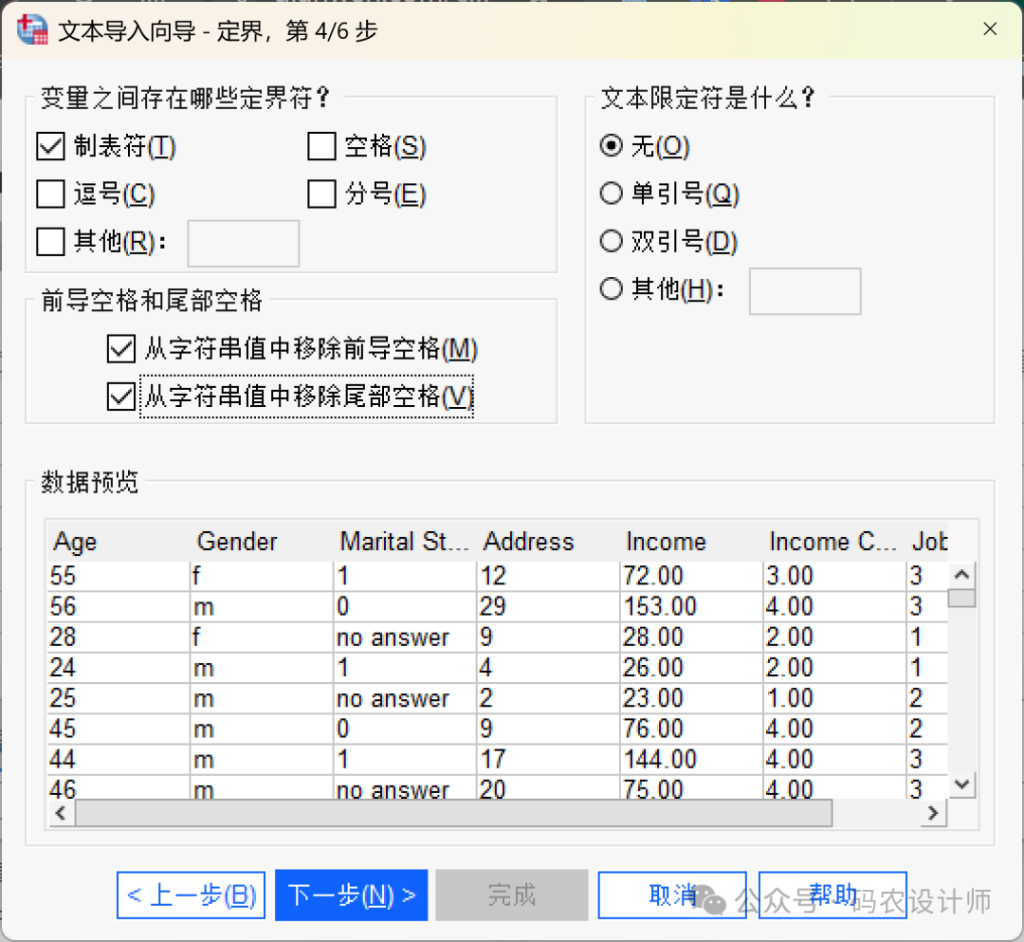
该步骤用于指定文本数据文件中使用的分隔符和文本限定符。还可以指定如何处理字符串值中的前导空格和尾部空格。
| 选项 | 含义 |
| 变量之间存在哪些定界(分隔)符 | 用于分隔数据值的字符或符号。可以选择空格、逗号、分号、制表符或其他字符的任意组合。对于没有中间数据值的多个连续分隔符,将被视为缺失值。 |
| 文本限定符 | 用于包围包含分隔符字符的值的符号。文本限定符会同时出现在值的开头和结尾,将整个值括起来。 |
| 前导空格和尾部空格 | 控制字符串值中前导和尾随空白空格的处理方式:从字符串值中移除前导空格:删除字符串值开头的所有空白空格。从字符串值中移除尾部空格:在计算字符串变量的定义宽度时,忽略值末尾的空白空格。如果选择空格作为分隔符,则多个连续的空白空格不会被视为多个分隔符。 |
具体来说,文本限定符的作用,是告诉SPSS哪些内容即使包含分隔符,也应被当作一个完整的文本值。例如,下面的示例中,逗号( , )既是列分隔符也是文本内容的一部分:
id,name,comment
1,张三,"我喜欢苹果,香蕉和橙子"如果没有文本限定符,SPSS会误以为是两列数据:
"我喜欢苹果 | 香蕉和橙子"设置了双引号作为文本限定符,SPSS就知道,双引号里面的内容是一个整体,即使中间有逗号,也不要拆分。
- 第5步:
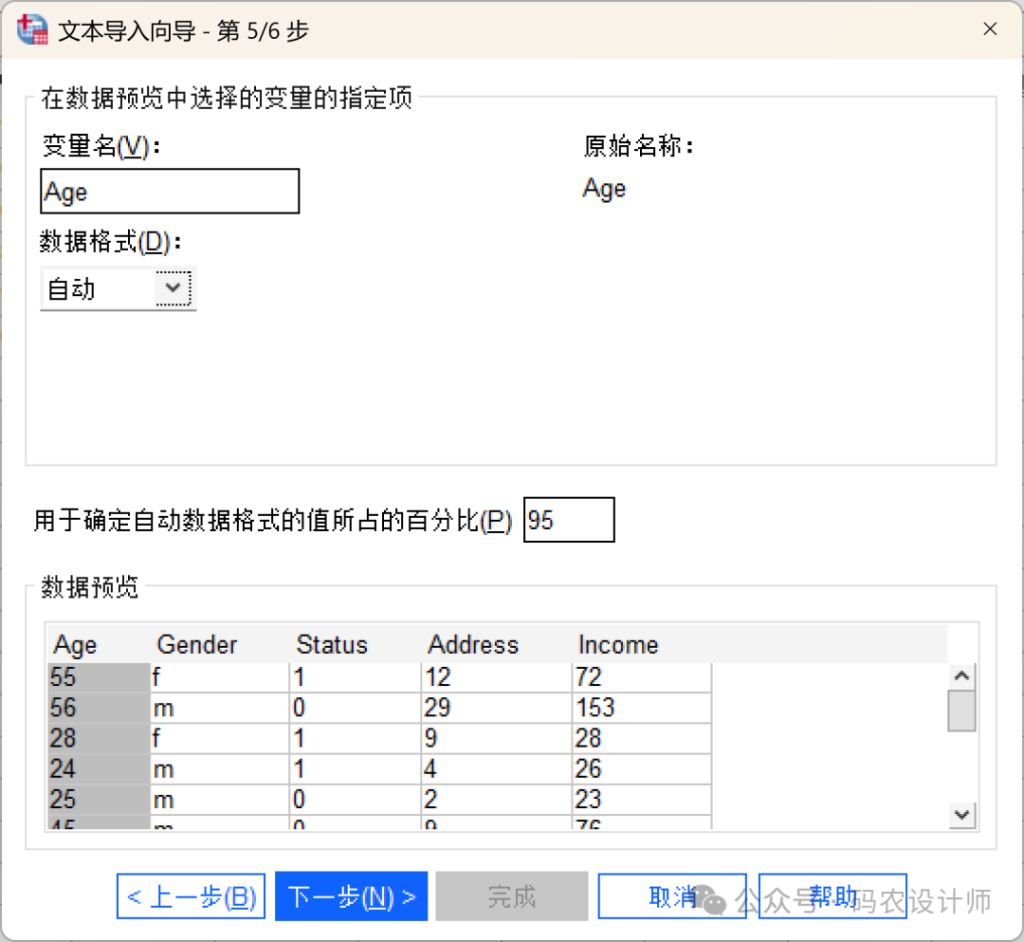
该步骤用于控制读取每个变量的变量名和数据格式,也可以指定要排除的变量。
| 选项 | 含义 |
| 变量名 | 可以用自定义变量名覆盖默认的变量名(需在下方预览窗口中选择变量)。如果从数据文件中读取的变量名不符合变量命名规则,将被自动修改。 |
| 数据格式 | 在下方预览窗口中选择一个变量,然后从列表中选择一种格式。其中:自动:系统将根据对所有数据值的评估来确定数据格式。不导入:从导入的数据文件中省略选定的变量。 |
| 用于确定自动数据格式的值所占的百分比 | 决定自动数据格式的值百分比。对于自动格式,每个变量的数据格式由符合同一格式的值的百分比来确定。该值必须大于 50。用于确定百分比的分母是每个变量的非空值数量。如果符合指定百分比的值没有使用一致的格式,则该变量将被分配字符串数据类型。对于基于百分比值分配了数值格式(包括日期和时间格式)的变量,不符合该格式的值将被分配系统缺失值。 |
- 第6步:
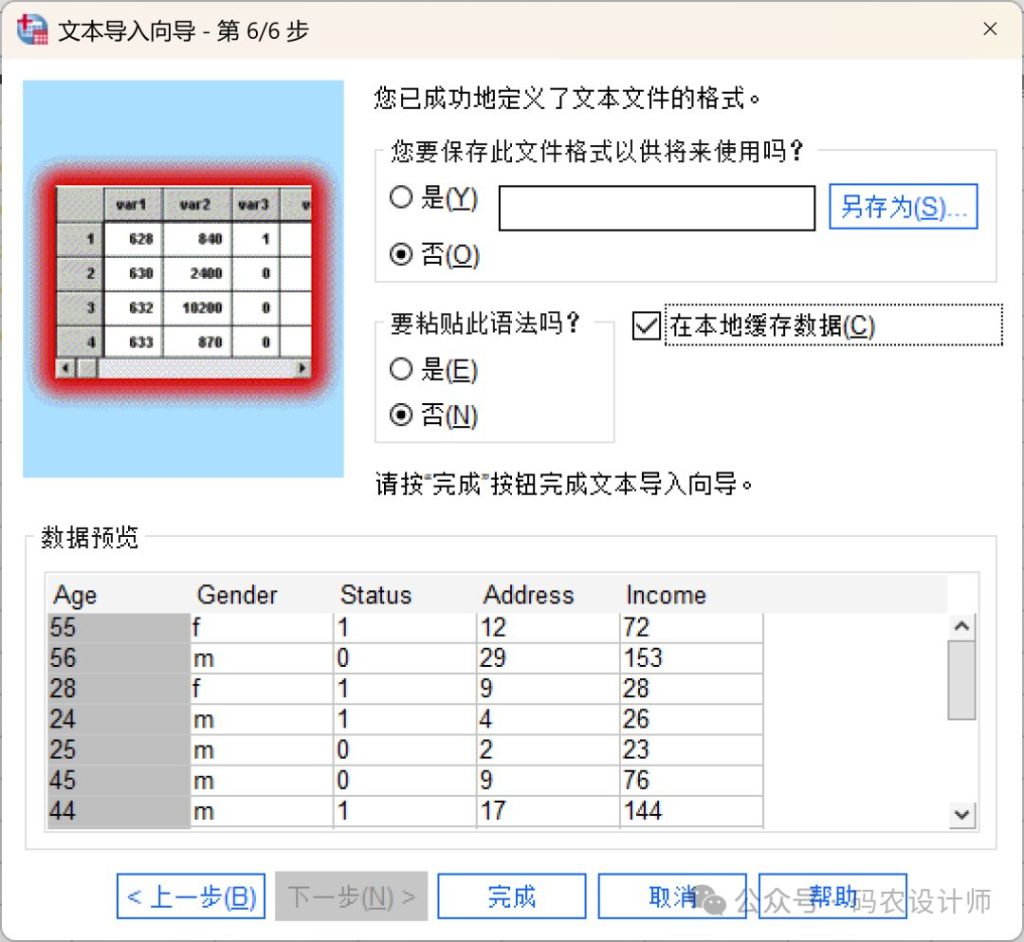
该步骤用于设置是否保存文件格式以供后续使用(用于第一步时加载预设格式)以及黏贴操作语法。
| 选项 | 含义 |
| 保存此文件格式以供将来使用 | 可以将当前的设置保存到一个文件中,以便在导入类似文本数据文件时重复使用。 |
| 黏贴此语法 | 可以将文本向导生成的语法粘贴到语法窗口中,之后可以对其进行编辑或保存,以供其他会话或操作中使用。 |
| 在本地缓存数据 | 数据缓存是数据文件的完整副本,存储在临时磁盘空间中。缓存数据文件可以提高系统性能。 |
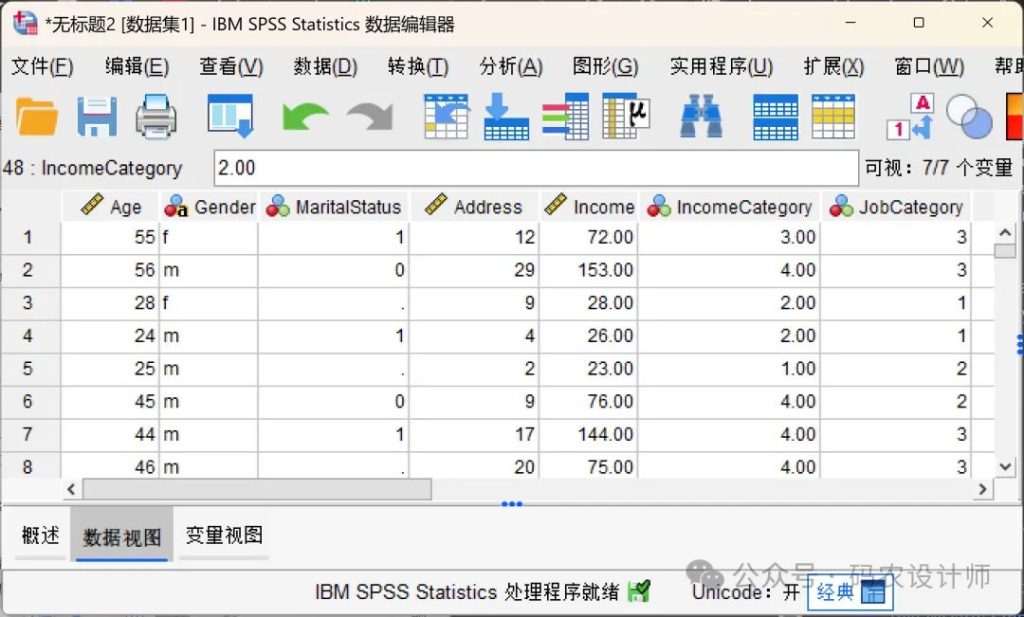
点击完成,SPSS会根据导入向导的设置将文本文件读入数据编辑器。
导入完成后,建议仔细检查导入结果,包括变量名是否正确、数据是否完整、变量类型是否恰当等,以确保数据准确无误地载入。
确认数据导入无误后,点击菜单栏「文件→保存」,将数据保存为「.sav」格式(SPSS默认格式)。日后如需再次使用,只需双击该.sav文件即可直接打开,无需重复导入文本数据。