只要安装了相应的数据库驱动程序,SPSS就可以从几乎所有类型的数据库中读取数据。在本地分析模式下,所需的驱动程序必须安装在本地计算机上;在分布式分析模式(需要使用IBM SPSS Statistics Server)下,驱动程序则必须部署在远程服务器端。
一、示例数据
SPSS可以通过【数据库向导(Database Wizard)】从数据库中导入数据。本文以Microsoft Access数据库为示例进行介绍。
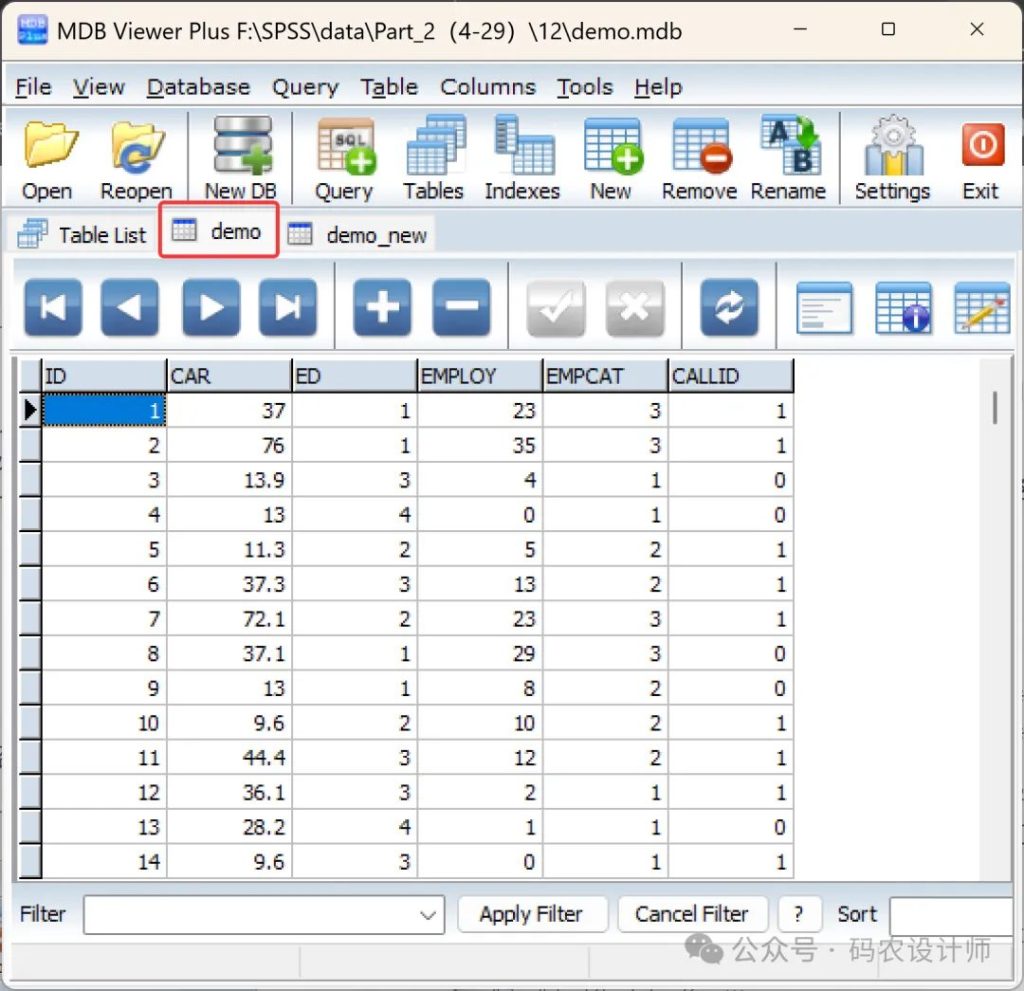
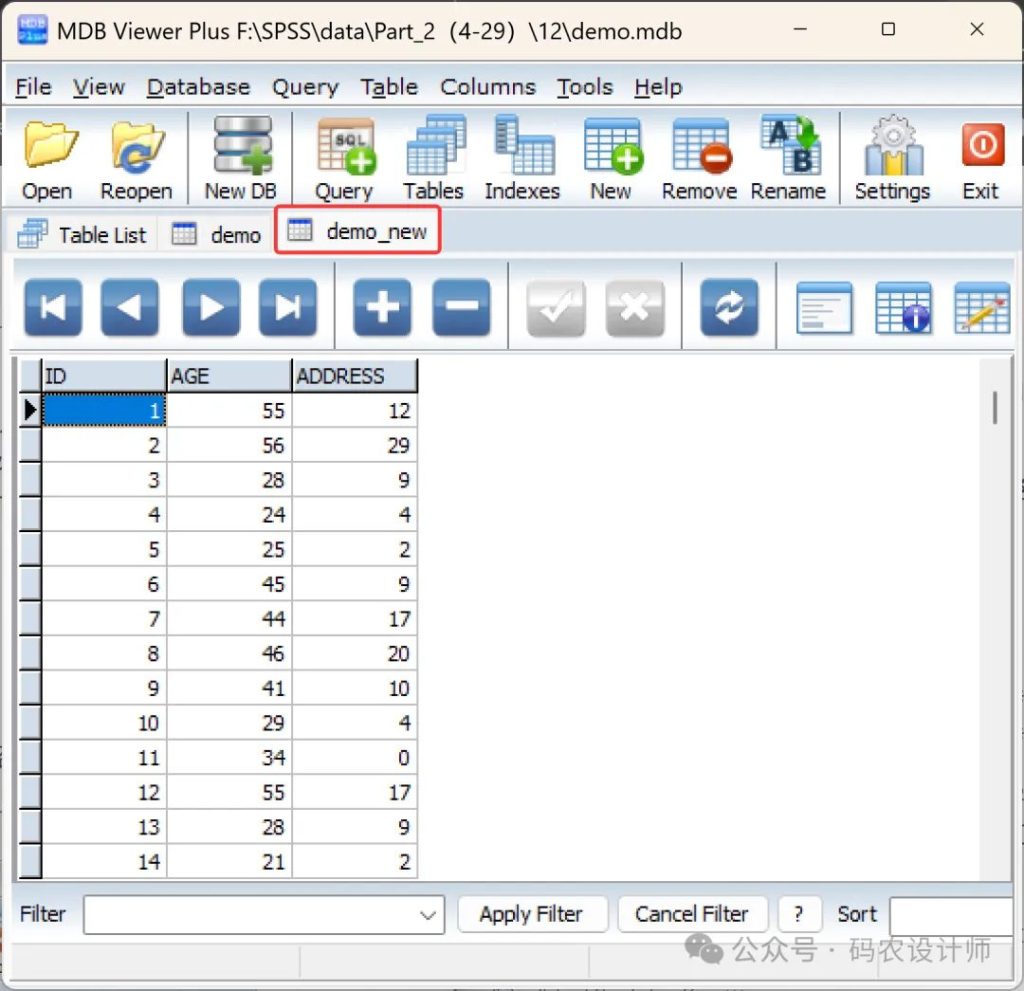
使用相应工具(如MDB Viewer Plus、MDBopener.com在线工具等)打开本次示例数据【demo.mdb】。可以看到数据库文件中包含「demo」和「demo_new」两个表,二者均有「ID」字段。后续数据读取时,将以该「ID」字段作为连接键,将两个表中的数据进行关联。
二、操作步骤
点击菜单栏【文件→导入数据→数据库→新建查询】,打开数据库向导界面,进行相应设置。
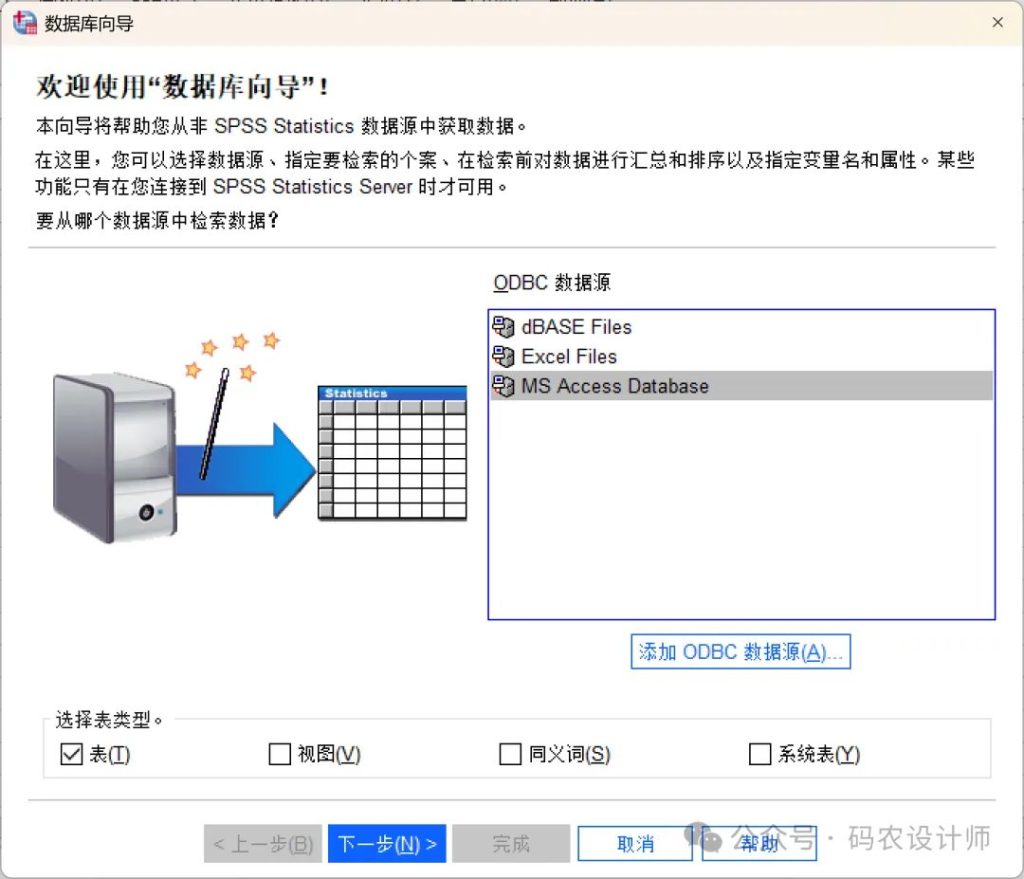
一、选择数据源:
从右侧可用的「ODBC数据源」列表中选择要连接的数据库类型(本次示例为MS Access Database),然后点击下一步。如需添加新的数据源,需单击「添加ODBC数据源」按钮。
一个ODBC数据源包含两个关键信息——用于访问数据的驱动程序,以及目标数据库的位置。需要注意的是,在定义数据源之前,必须先安装与该数据库类型相匹配的驱动程序。
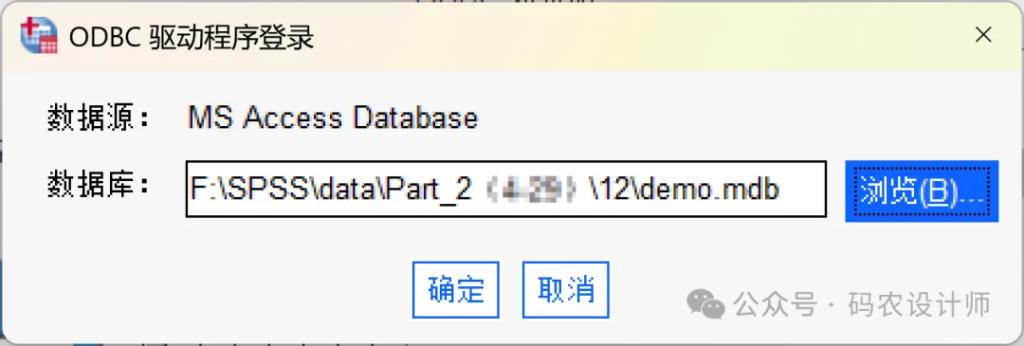
点击浏览按钮,选择目标数据库文件(本次示例为demo.mdb),点击确定。有些数据源可能需要输入登录名、密码及其他信息。
二、选择表和字段:
该步骤用于控制读取哪些表和字段,数据库字段(列)将作为变量读取。
- 显示字段名称:单击表名左侧的加号(+)可列出表中的字段,单击表名左侧的减号(-)可隐藏字段。
- 添加字段:双击「可用的表」列表中的任意字段,或将其拖到「以此顺序检索字段」列表中。可以通过在字段列表内拖放字段来重新排序。
- 移除字段:双击「以此顺序检索字段」列表中的任意字段,或将其拖到「可用表」列表中。
- 对字段名称进行排序:如果选中「对字段名进行排序」复选框,「数据库向导」将以字母顺序显示可用字段。
默认情况下,可用表列表仅显示标准数据库表。可以通过以下复选框控制列表中显示的项目类型:
- 表:标准数据库表。
- 视图:由查询定义的虚拟或动态表。可以包含多个表的连接和(或)基于其他字段值计算得出的字段。
- 同义词:表或视图的别名,通常在查询中定义。
- 系统表:系统表定义数据库属性。在某些情况下,标准数据库表可能被归类为系统表,只有选择该选项时才会显示。对真实系统表的访问通常仅限于数据库管理员。
需要注意的是:
- 对于OLE DB数据源(仅在Windows操作系统上可用),只能从单个表中选择字段,该数据源不支持多表连接。
- 如果选定了表中的任何字段,在后续的「数据库向导」窗口中,该表的所有字段都将可见,但只有在该步骤中选定的字段才会作为变量导入。这使我们能够使用不导入的字段创建表连接和指定条件。
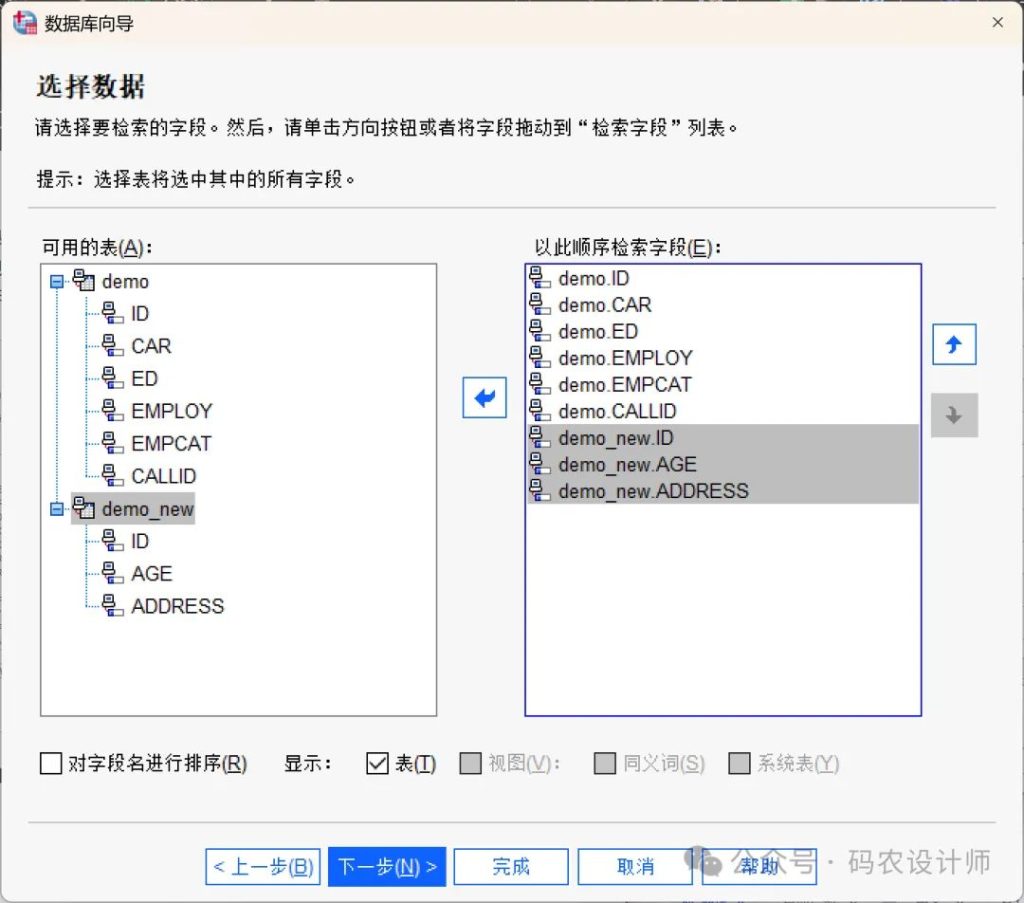
三、指定表之间的关系:
该步骤用于定义ODBC数据源表之间的关系。如果选择了来自多个表的字段,则必须至少定义一个连接(Join)。
- 建立关系:从任意表中拖动一个字段到希望连接的目标字段上即可创建关系,「数据库向导」会在两个字段之间绘制一条连接线,指示它们的关系。需要注意的是,这些字段必须是相同的数据类型。
- 自动连接表:根据主键/外键或匹配的字段名和数据类型,尝试自动连接表。
- 连接类型:如果驱动程序支持外连接,可以指定内连接、左外连接或右外连接。
| 连接类型 | 含义 | |
| 内连接 | 仅包含相关字段值相等的行。 | |
| 外连接 | 除了内连接的一对一匹配外,还可以使用外连接来合并具有「一对多」匹配方案的表。 | |
| ① | 左外连接 | 包含「左侧」表中的所有记录;对于「右侧」表,仅包含相关字段相等的那些记录。 |
| ② | 右外连接 | 包含「右侧」表中的所有记录;对于「左侧」表,仅包含相关字段相等的那些记录。 |
本次示例基于共同的「ID」字段进行内连接。
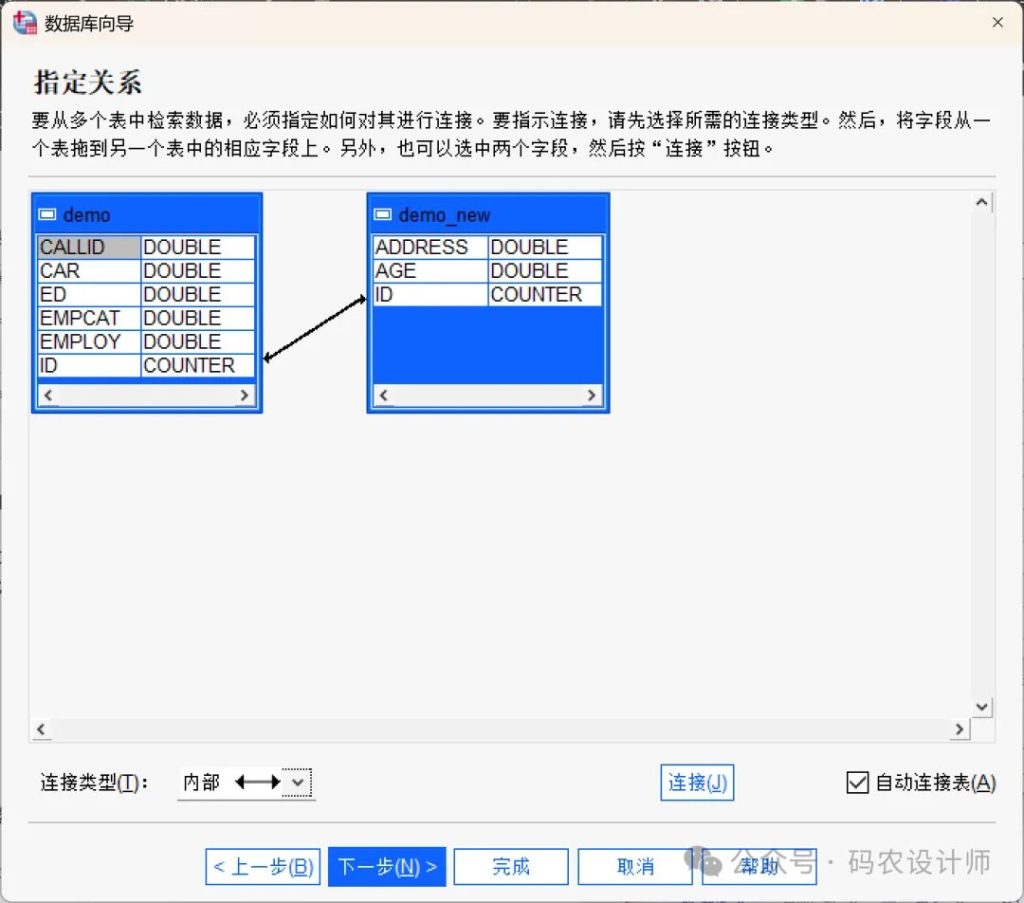
四、指定数据的选择条件:
该步骤用于指定选择个案子集(行)的标准。
| 选项 | 含义 |
| 条件 | 条件由两个表达式及它们之间的一些关系组成。表达式为每个个案返回一个值(真、假或缺失)。如果结果为真,则选择该个案;如果结果为假或缺失,则不选择该个案。要构建条件,至少需要两个表达式和一个连接表达式的关系。可使用六个关系运算符(<、>、<=、>=、= 和 <>)中的一个或多个。表达式可以包括字段名、常量、算术运算符、数值和其他函数以及逻辑变量。可以使用不作为变量导入的字段。 |
| 函数 | 提供一系列内置的算术、逻辑、字符串、日期和时间SQL函数。可以将函数从列表拖到表达式中,也可以输入任何有效的SQL函数。 |
| 随机抽样个案 | 从数据源中选择个案的随机样本。对于大型数据源,将个案数量限制为一个小的、有代表性的样本,可显著减少运行过程所需的时间。抽样方法:如果数据源支持,数据库随机抽样比IBM SPSS Statistics随机抽样更快,因为IBM SPSS Statistics随机抽样仍必须读取整个数据源以提取随机样本。样本大小:包含以下两种抽样方法:①、按近似百分比抽样:从全部个案中随机抽取指定比例的样本。该过程对每个个案独立进行伪随机判断,因此实际抽取的案例比例仅近似于预设百分比。数据文件中的个案总量越大,选择的个案百分比就越接近指定的百分比。②、按精确数量抽样:从个案总数中精确抽取指定数量的随机样本。若请求抽取的个案数超过数据文件中的实际个案总数,最终样本将按实际个案总数进行等比缩减,导致样本量少于原定请求数量。 |
| 提示输入值 | 在查询中嵌入提示以创建参数查询。 |
在本次示例中,通过设置表达式仅导入前100个个案。
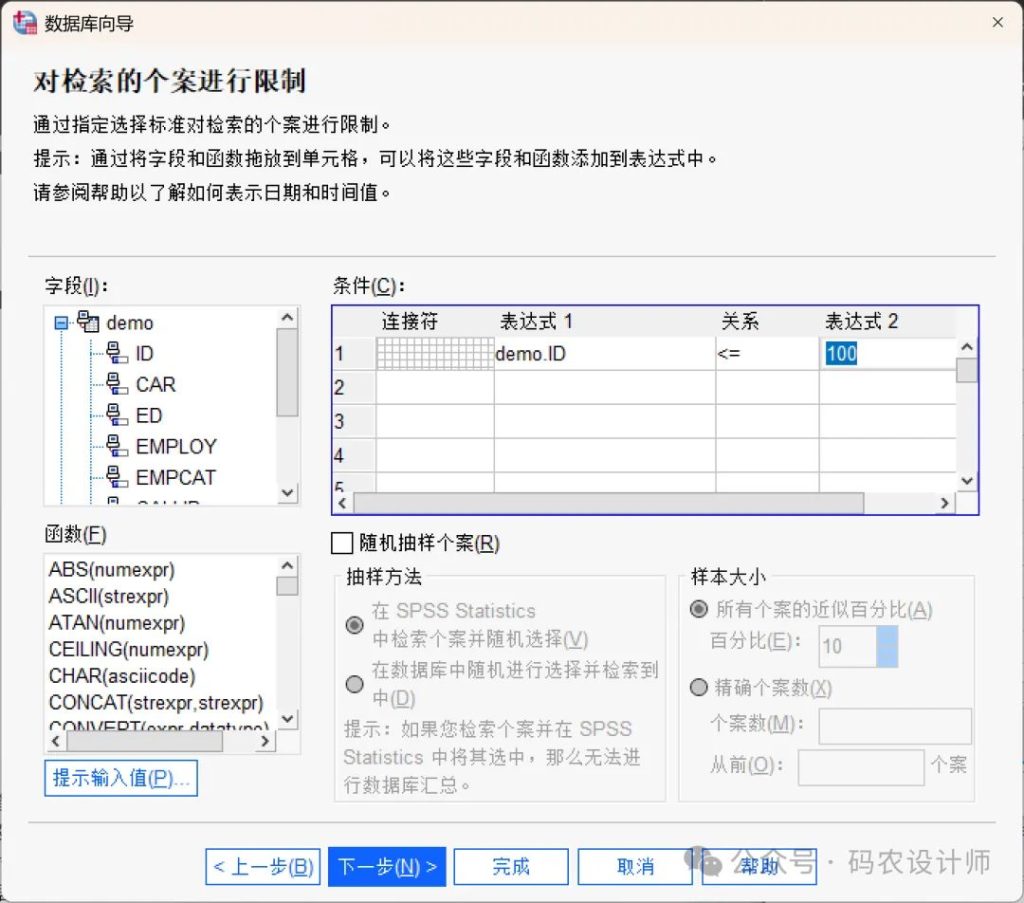
- 创建参数查询:
在查询中嵌入提示可以创建参数查询。当用户运行查询时,系统将根据此处设置的内容提示用户输入信息。当需要从同一数据源获取不同的数据视图时,该功能尤为实用。例如,使用同一个查询查看不同财政季度的销售数据。
要创建提示,需将光标置于任一「表达式」单元格中,然后点击「提示输入值」按钮。使用「提示输入值」会创建一个对话框,该对话框将在每次运行查询时向用户索取必要信息。
构建提示时,需输入提示字符串和默认值。提示字符串将在用户每次运行查询时显示,应明确说明需要输入何种信息。如果用户不是从列表中进行选择,字符串还应提供有关输入格式的说明。例如,请输入季度 (Q1, Q2, Q3, ...)。
如果勾选「允许用户从列表中选择值」复选框,可以将用户的选择限制在提供的值范围内,各值之间以换行符分隔。如果数据类型为日期时,日期和时间值必须以特定格式输入。其中,日期值必须使用通用形式「yyyy-mm-dd」;时间值必须使用通用形式「hh:mm:ss」;日期/时间值(时间戳)必须使用通用形式「yyyy-mm-dd hh:mm:ss」。
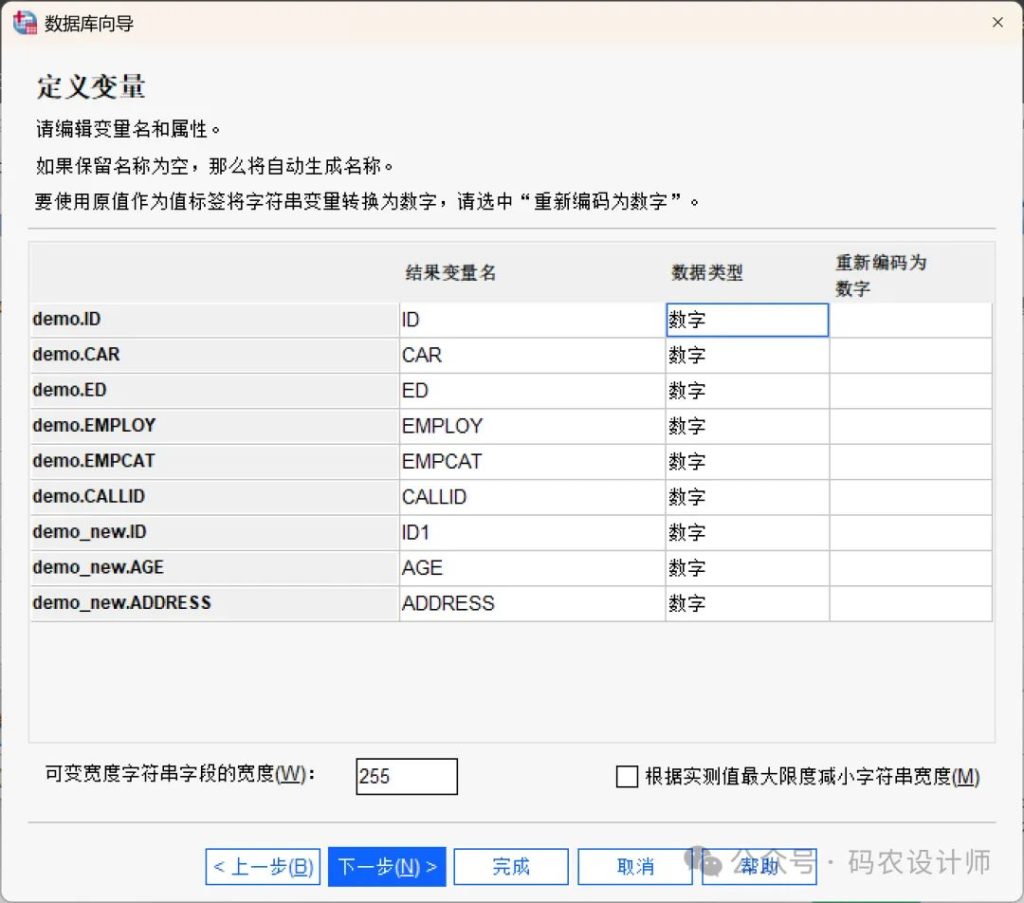
五、定义变量名与数据类型:
在定义变量阶段,字段名会自动被用作变量名。如果字段名不符合SPSS变量命名规则,SPSS会自动转换成合法的变量名,原始字段名则会保留为变量标签。
- 将字符串转换为数值:如果希望将字符串变量自动转换为数值变量,可选中该字符串变量对应的「重新编码为数字」复选框。字符串值将根据原始值的字母顺序被转换为连续的整数值,且原始值会作为值标签保留在新变量中。
- 可变宽度字符串字段的宽度:该选项控制可变宽度字符串值的宽度。默认宽度为255字节,且仅读取前255字节(通常在单字节语言中为255个字符)。宽度最大可设置为32767字节,虽然不希望截断字符串值,但也不应指定过大的值,因为这会导致处理效率低下。
- 基于实测值最大限度减小字符串宽度:根据每个字符串变量中最长的观测值,自动设置其宽度。
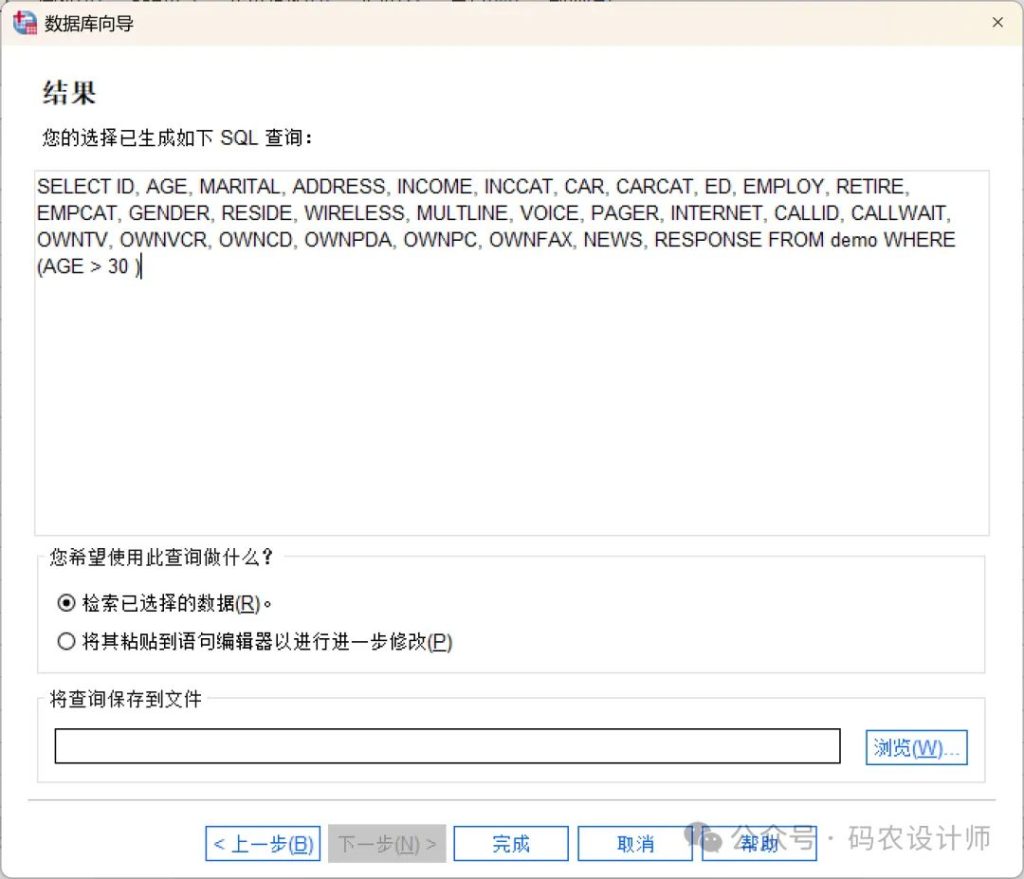
六、生成 SQL 语句并导入:
在最后一步,数据库向导会显示基于向导选择自动生成的SQL语句,可以选择立即执行SQL或者保存SQL到文件以后重用。
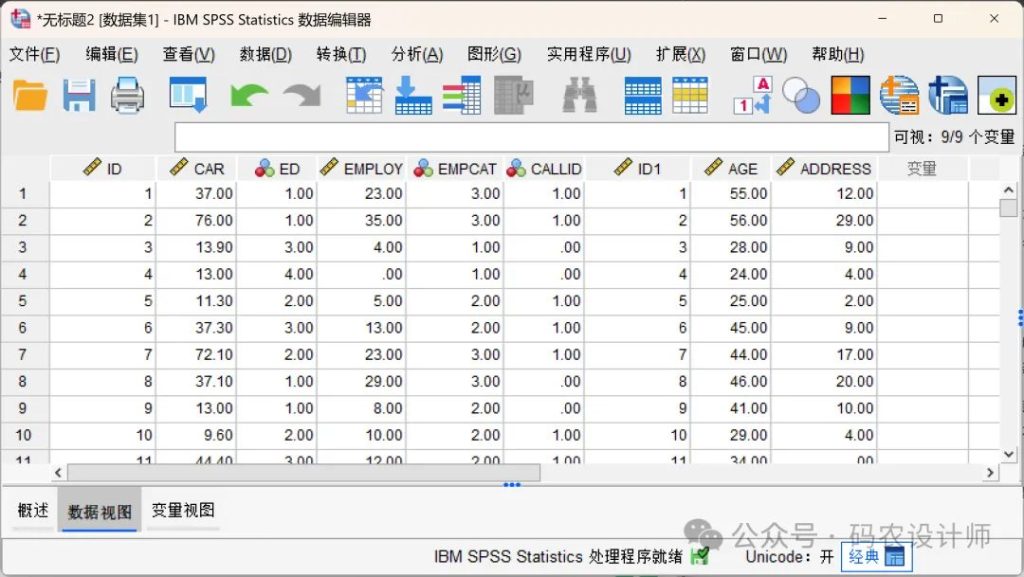
点击完成,SPSS会根据导入向导的设置将数据库文件读入数据编辑器。
本次仅介绍日常最多使用的四种数据格式文件(SPSS Statistics格式文件、Excel文件、文本文件、数据库文件),更多格式数据文件的读取操作可以查看官方文档:
https://www.ibm.com/docs/zh/spss-statistics/31.0.0?topic=files-opening-data