本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj 提取码:mnsj
如有需要请尽快下载。如若失效,我也会在最新发布文章中更新下载链接。 聚类分布制图 工具集 可通过执行聚类分析来识别具有统计显著性的热点、冷点和空间异常值的位置。这些工具在需要根据一个或多个聚类的位置执行某些行动时特别有用,例如在需要分配更多的警力来处理一组集中出现的入室盗窃案时,或者需要确定疾病爆发的地点以找到疾病根源的线索时。
此外,与之前介绍的 “分析模式”工具集只能回答“是否存在空间聚类”这样的问题不同,“聚类分布制图”工具可以更加直观地呈现聚类位置和范围,所解答的问题是“聚类(热点/冷点)的出现位置在哪里”、“空间异常值的出现位置在哪里”以及“哪些要素最相似”。 聚类分布制图 工具集包含聚类和异常值分析、分组分析、热点分析、优化的热点分析、优化的异常值分析、相似搜索 六个工具。
本次主要介绍 分组分析 工具。
分组分析 可以根据用户指定的要素属性和可选的空间或时间约束,将数据集分割成若干个具有相似特性的组或类别。这个工具非常有用,因为它可以帮助用户理解和解释复杂数据集中的模式和结构。
----------------
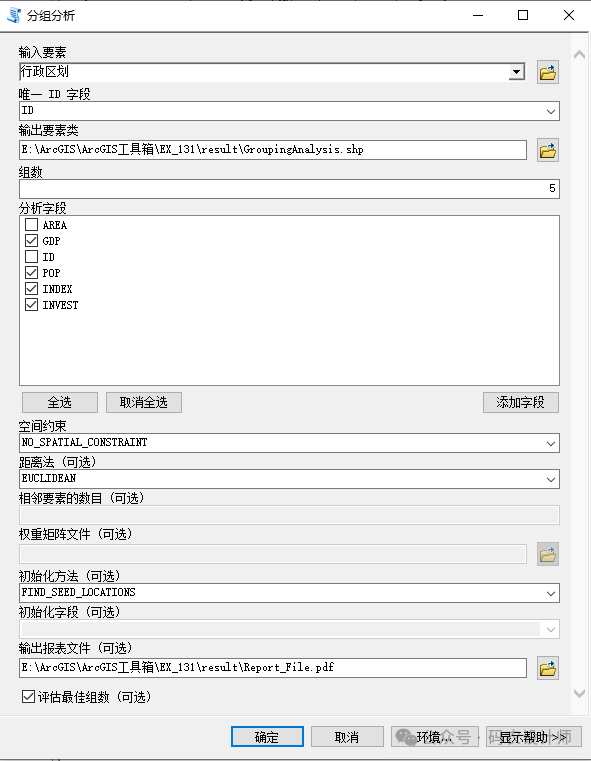
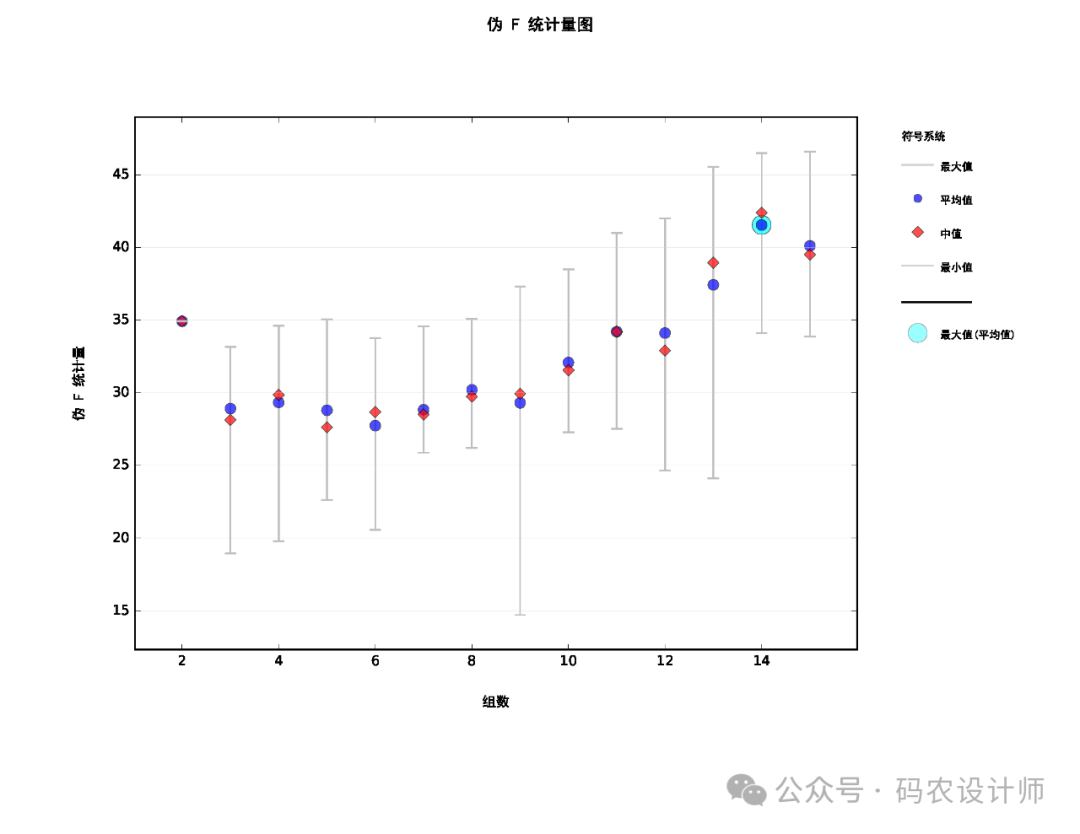
该工具包含多个参数,在使用工具时,需要根据具体的数据和分析目标来合理设置这些参数。通过调整这些参数,可以探索数据中的不同分组模式,从而更好地理解数据的内在结构和关系 : 该工具 通过唯一 ID 字段可以将输出要素类中的记录链接回原始输入要素类中的数据。因此,每个要素的唯一 ID 字段值都必须唯一,而且通常应该是一个与要素类一同保留的永久性字段。需要注意的是,要素自带的FID/OID 字段不可用。 用于分组分析的字段或属性。 分析字段应为数值型字段,而且应包含各种值。 无任何变化的字段(即每个记录的值相同)将从分析中删除,但将包括在输出要素类中。 虽然倾向于引入尽可能多的分析字段,但对该工具而言,最好从单个变量开始构建。 较少的分析字段的结果更易于解释。 而且,字段较少时,还易于确定哪些变量是最佳辨别因素。 指定希望将数据分成的组数。这个参数直接影响分组结果的粒度,组数越多,分组越细致,反之则分组更为宽泛。 有时,可能不 知道最适合于数据的组数,此时 ,则必须尝试不同的组数,注意哪些值能够最恰当地对组进行区分。 当选中评估最佳组数参数时,将对具有 2 至 15 个组的分组解决方案计算伪 F 统计量(用于反映组内相似性和组间差异性 )。 如果没有其他标准指导您选择组数,可使用与其中一个最大伪 F 统计量值相关的数字。 如果指定了一个可选的输出报表文件,该 PDF 报表将包括一个图,该图显示具有 2 到 15 个组的解决方案的 F 统计量值。 定义分组过程中是否要考虑要素之间的空间关系。例如,可以选择只有相邻的要素才能被分到同一组,或者基于特定的空间连接方式来约束分组。这有助于确保分组结果在地理空间上具有连续性或特定的空间模式。该工具提供了多种空间约束选项: 只有那些共享一条边的相邻要素才能被分到同一组。换句话说,分组会基于要素的边界是否直接相连。
CONTIGUITY_EDGES_CORNERS:
在这个模式下,分组会考虑那些共享一条边或者一个角的相邻要素。这比“共享边 ”选项更为宽松,因为它允许角落相连的要素也被视为相邻。 Delaunay三角剖分是一种将空间划分为一系列相连的、但不重叠的三角形的算法。当选择这个选项时,分组会基于Delaunay三角剖分的结果,确保同一个组中的要素在三角剖分中具有公共边 。 这个选项会根据每个要素的K个最近邻居来进行分组。K是一个自定义的参数,表示每个要素在分组时会考虑其最近的K个邻居。这种方法不依赖于要素是否直接相邻,而是基于距离来确定邻居关系。
GET_SPATIAL_WEIGHTS_FROM_FILE:
这个选项允许用户从一个外部文件中加载空间权重矩阵,该文件定义了要素之间的空间关系。提供了更大的灵活性,可以根据特定的研究需求或复杂的空间关系模型来定义分组时的空间约束。可以使用生成空间权重矩阵或生成网络空间权重工具创建空间权重矩阵文件。 选择这个选项意味着在分组过程中不会应用任何空间约束。分组将完全基于属性数据的相似性,而不考虑要素之间的空间位置关系。当选择该选项时,需要设置初始化字段参数用于确定分组的种子点,即分组开始的起点。包括以下三个选项: 1)、 FIND_SEED_LOCATIONS:该 选 项 允许工具自动查找种子位置。工具会随机选择一个种子,并确保后续选择的种子在数据空间中相互远离,以此来增加分组的多样性并确保分组的代表性。该 选 项 通常用于没有明确先验知识的情况,让算法自动选择起始点。2)、 GET_SEEDS_FROM_FIELD:如果已经有一个特定的字段用于标识哪些要素应作为种子点,则可以选择该选项,此时需要 在 初始化字段处选择该字段。该 选 项 允许用户根据先验知识或特定需求来手动指定种子点。3)、 USE_RANDOM_SEEDS:该 选项会随机选择种子点。每次运行分析时,由于种子的随机性,结果可能会有所不同。该 选 项 适用于想要探索数据的多种可能分组情况,或者进行灵敏度分析。这些空间约束选项提供了在分组分析中融入不同级别的空间关系考虑的能力,从而可以更精确地满足特定的分析需求。 该工具的默认输出是一个新的输出要素类,其中包含分析中使用的字段,以及一个名为 SS_GROUP 的用于标识每个要素所属的组的新整型字段。 如果为空间约束参数选择了 NO_SPATIAL_CONSTRAINT,则输出要素类还将包含一个名为 SS_SEED 的新二进制字段。 SS_SEED 字段可指明使用哪些要素作为分组的起点。 SS_SEED 字段中非零值的数量将与为组数参数所输入的值相匹配。 2、分组分析报表文件:
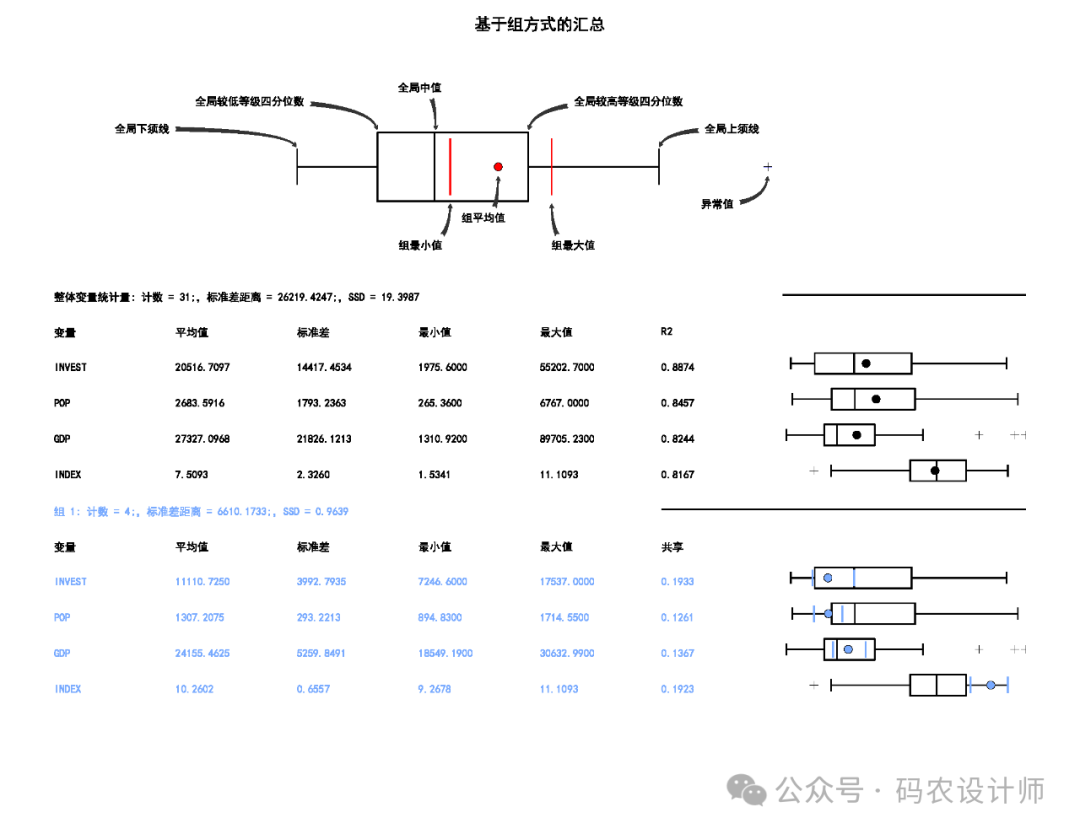
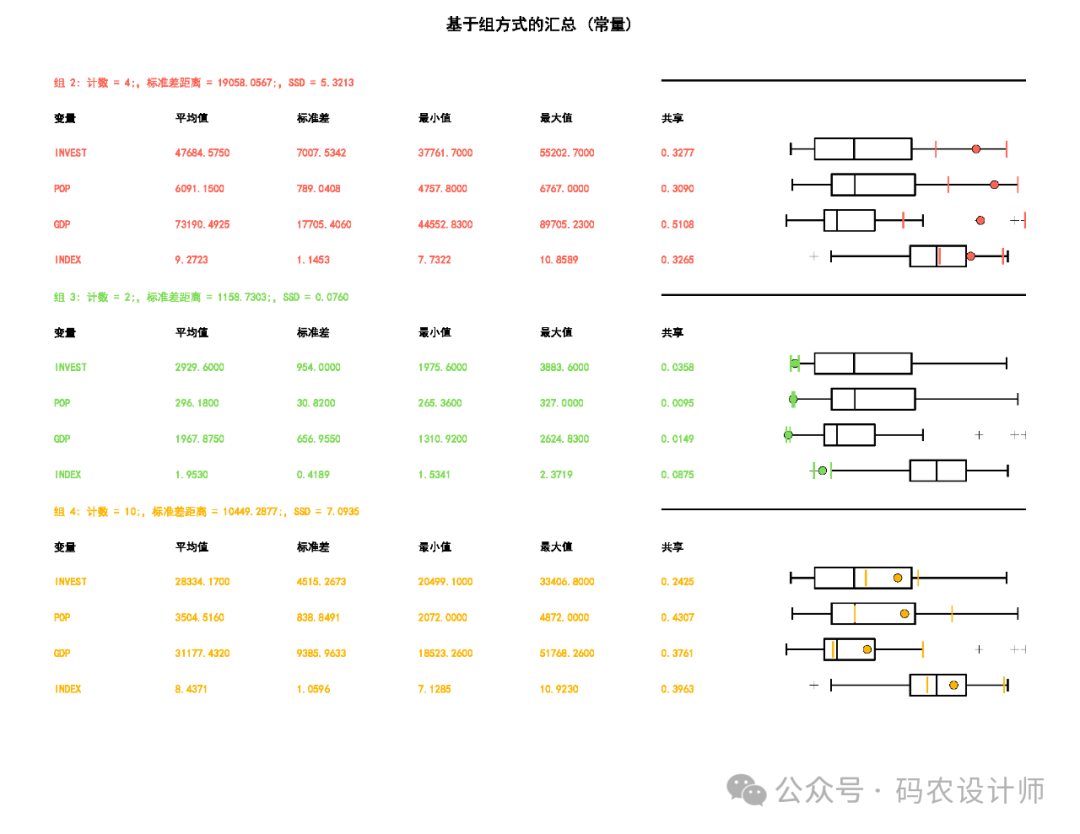
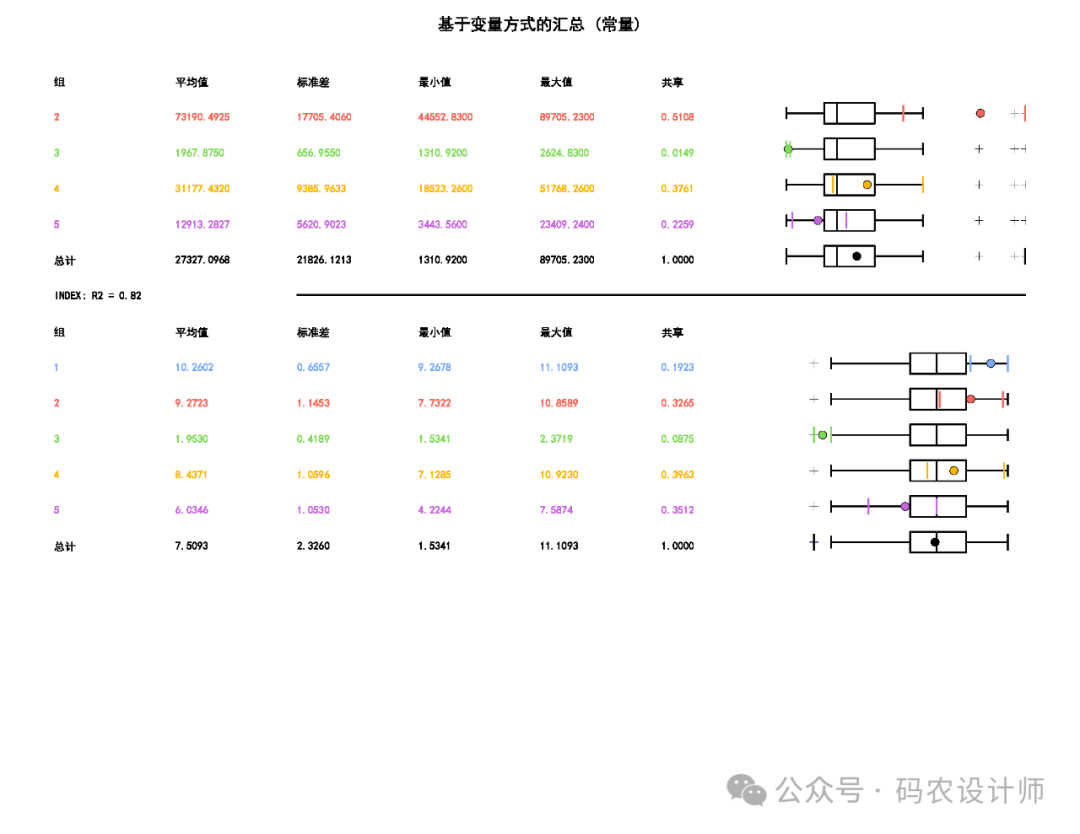
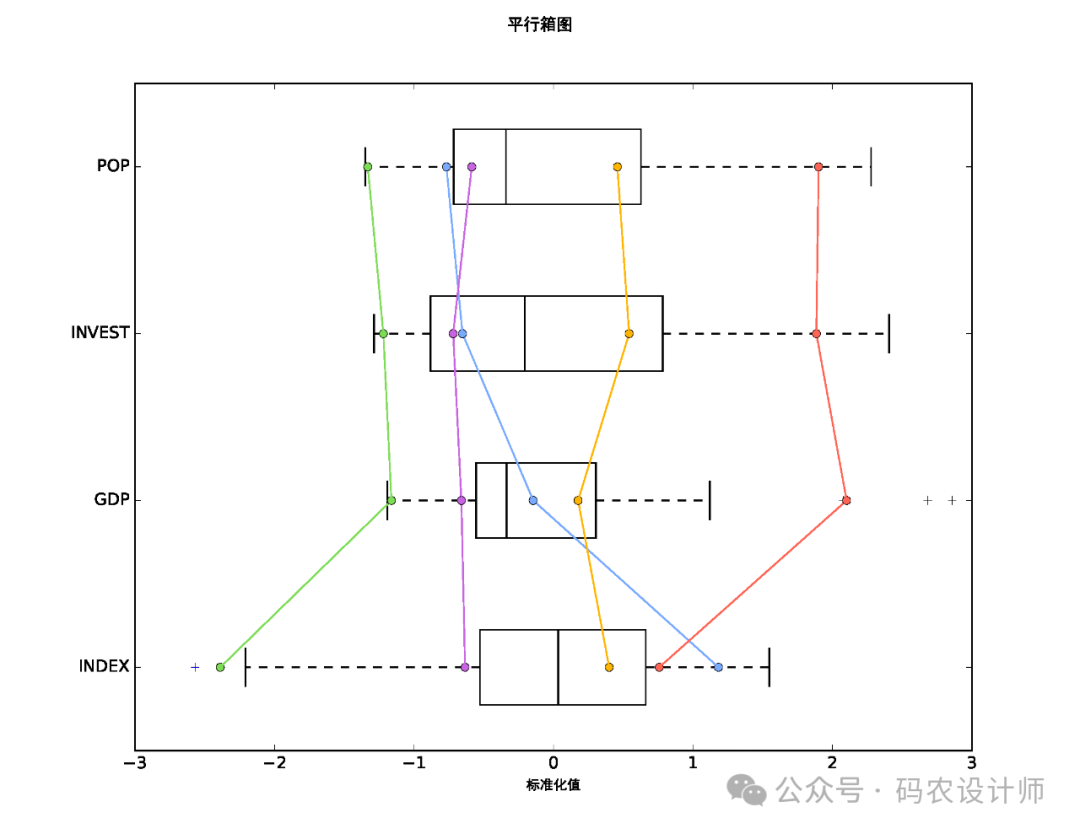
如果为输出报表文件参数指定了路径,则会创建一个用于汇总所创建组的 PDF。 此报表包含各种表格和图形,用于展示分组分析的结果和各种统计信息, 可帮助了解所确定的组的特征。主要包括以下内容: 该部分会对每个组中的各个变量(分析字段)进行相互比较。 这些统计数据是针对每个分析字段中所有数据的全局均值、标准差 (Std.Dev.)、最小值、最大值和 R2 值。 某个特定变量的 R2 值越大,该变量区分要素的性能越好 。 在全局汇总之后 , 将报告每个组中每个变量的均值、标准差、最小值、最大值和共享值。 该部分会 比较每个组的变量范围,一次一个分析字段(变量)。通过这种方式,很容易了解哪个组中的每个变量具有最高和最低值范围。 当选中评估最佳组数参数时,报表文件将包括伪 F 统计量值的图表。图表上的圆点是最大 F 统计量,表示使用多少个组来区分指定的要素和变量最有效。
分组分析工具在多个领域都有广泛的应用,包括市场分析、社会科学研究、环境监测等。例如,在市场分析中,可以使用分组分析工具将消费者划分为不同的细分市场,以便更好地理解他们的需求和偏好。
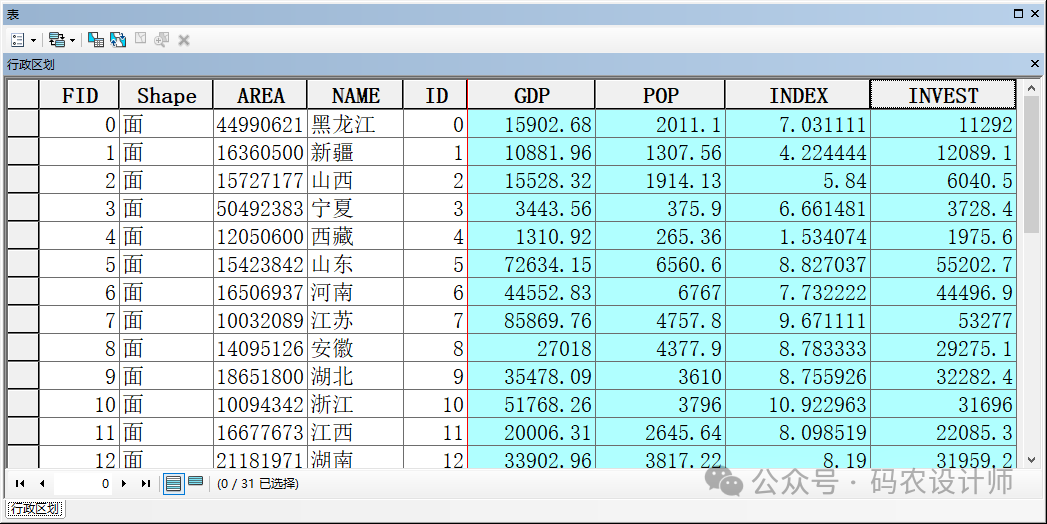
加载【行政区划】面要素。 属性表中有表示 各省市GDP、年末就业人口、固定资产投资、市场化指数的四个字段。选择【系统工具箱→Spatial Statistics Tools→聚类分布制图 →分组分析
创建的新输出要素类,其中包含所有要素、指定的分析字段以及一个用于指明每个要素所属组的字段。
汇总组特征的 PDF 报表文件:
本篇文章来源于微信公众号: 码农设计师







{kind=link}