Python受欢迎的原因之一就是其计算生态丰富,据不完全统计,Python 目前为止有约13万+的第三方库。
本系列将会陆续整理分享一些有趣、有用的第三方库。
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1FSGLd7aI_UQlCQuovVHc_Q?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/Python_Ecosystem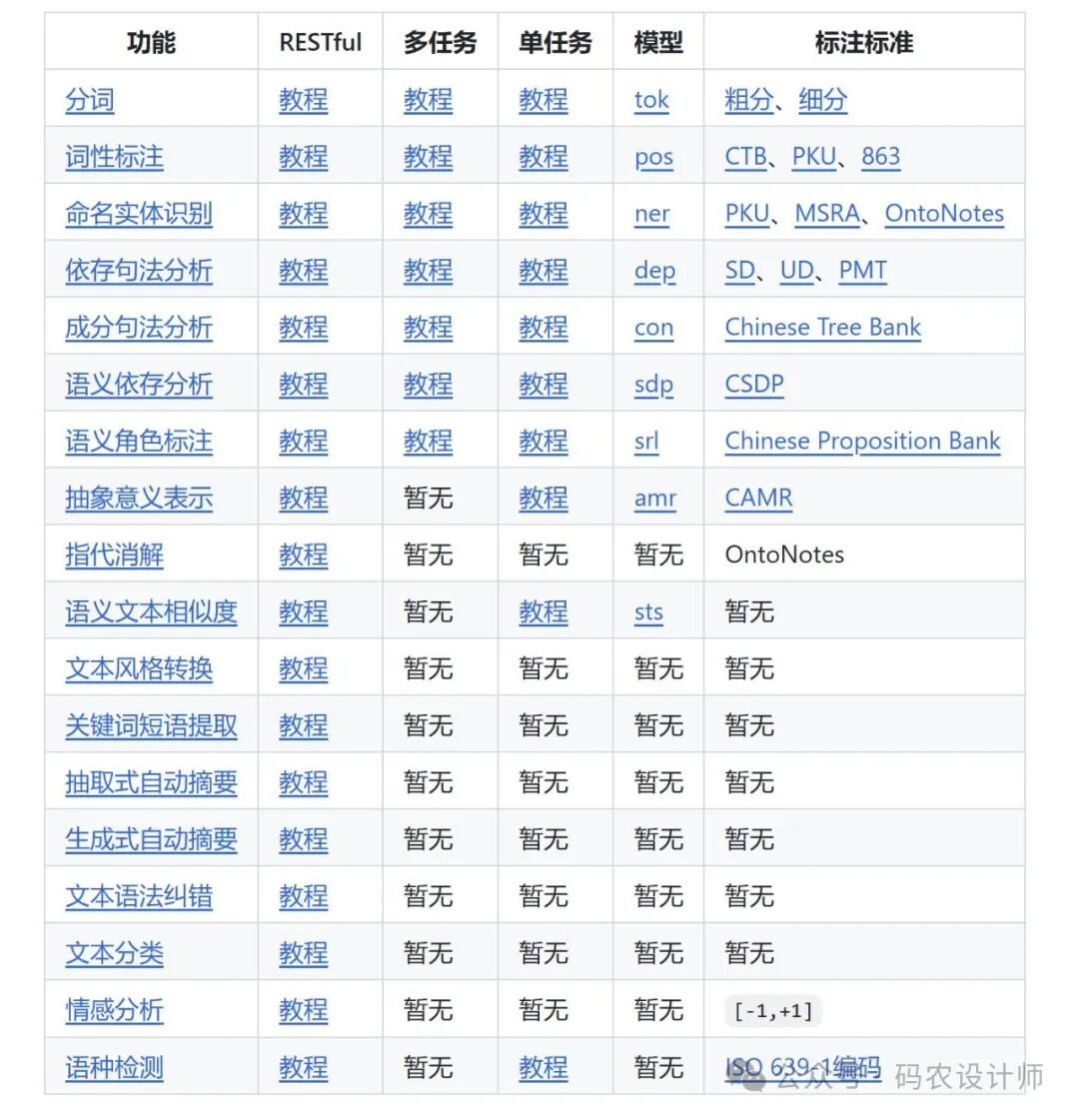
-
安装:
-
轻量级RESTful API:
# 轻量级RESTful APIpip install hanlp_restful
-
海量级native API:
# 海量级native APIpip install hanlp
https://github.com/hankcs/HanLPHanLP发布的模型分为多任务和单任务两种,多任务速度快省显存,单任务精度高更灵活。
-
多任务模型:
import hanlp
# 查看可用的多任务模型
print(hanlp.pretrained.mtl.ALL)
# 加载预训练的多任务学习模型(支持分词、词性标注、NER、依存分析等)
mtl = hanlp.load(hanlp.pretrained.mtl.CLOSE_TOK_POS_NER_SRL_DEP_SDP_CON_ELECTRA_SMALL_ZH) # 世界最大中文语料库
# 输入文本
text_list = ['HanLP为生产环境带来次世代最先进的多语种NLP技术。']
# 执行多任务模型
mtl_result = mtl(text_list)
# print(mtl_result)
# 美化输出结果
mtl_result.pretty_print()
输出结果:
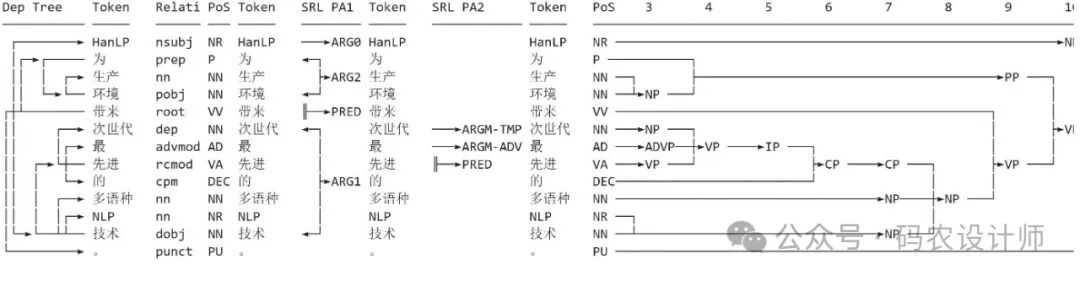
还可以通过tasks参数传递指定任务名称列表,来指定任务。
# 指定任务
tasks_list = ['tok', 'pos']
mtl_result = mtl(text_list, tasks=tasks_list)
print(mtl_result)
输出结果:
{
"tok/fine": [
["HanLP", "为", "生产", "环境", "带来", "次世代", "最", "先进", "的", "多语种", "NLP", "技术", "。"]
],
"pos/ctb": [
["NR", "P", "NN", "NN", "VV", "NN", "AD", "VA", "DEC", "NN", "NR", "NN", "PU"]
]
}
-
单任务模型:
# 加载预训练的分词和词性标注模型(首次运行自动下载)
tokenizer = hanlp.load(hanlp.pretrained.tok.COARSE_ELECTRA_SMALL_ZH)
tagger = hanlp.load(hanlp.pretrained.pos.CTB9_POS_ELECTRA_SMALL)
# 进行分词和词性标注
text = "HanLP是一套用Java编写的自然语言处理工具包"
words = tokenizer(text)
pos_tags = tagger(words)
print(list(zip(words, pos_tags)))
# 输出:[('HanLP', 'NR'), ('是', 'VC'), ('一套', 'AD'), ('用', 'P'), ('Java', 'NN'), ('编写', 'VV'), ('的', 'DEC'), ('自然', 'NN'), ('语言', 'NN'), ('处理', 'NN'), ('工具包', 'NN')]
HanLP = hanlp.pipeline()
.append(hanlp.utils.rules.split_sentence, output_key='sentences')
.append(hanlp.load('FINE_ELECTRA_SMALL_ZH'), output_key='tok')
.append(hanlp.load('CTB9_POS_ELECTRA_SMALL'), output_key='pos')
.append(hanlp.load('MSRA_NER_ELECTRA_SMALL_ZH'), output_key='ner', input_key='tok')
.append(hanlp.load('CTB9_DEP_ELECTRA_SMALL', conll=0), output_key='dep', input_key='tok')
.append(hanlp.load('CTB9_CON_ELECTRA_SMALL'), output_key='con', input_key='tok')
doc = HanLP('HanLP为生产环境带来次世代最先进的多语种NLP技术。预训练了十几种任务上的数十个模型')
print(doc)
# 美化输出结果
doc.pretty_print()
更多内容可以前往官方文档查看:
https://hanlp.hankcs.com/docs/

本篇文章来源于微信公众号: 码农设计师
{kind=link}