本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1jG-rGG4QMuZu0t0kEEl7SA?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/Data_Visualization函数语法:
plt.violinplot(dataset, positions=None, *, vert=None,orientation='vertical', widths=0.5,showmeans=False, showextrema=True,showmedians=False, quantiles=None,points=100, bw_method=None, side='both',data=None)
-
dataset:必需参数,需要绘制的数据序列,格式为列表 / 数组,每个元素是一组数据。 -
positions:设置小提琴图的 x 轴位置(如positions=[1,3,5],让图间隔更宽); -
vert、orientation:两者作用类似,控制小提琴图的方向。vert=True(默认)或 orientation='vertical'表示垂直方向显示( violin 竖放)。vert=False 或 orientation='horizontal'表示水平方向显示( violin 横放); -
widths:控制小提琴图的宽度,默认 0.7。可以是单个数值(所有小提琴宽度相同),或列表(为每组数据指定不同宽度); -
showmeans:是否显示均值(布尔值,默认 False),显示后用短线标记; -
showextrema:是否显示极值(布尔值,默认 True),显示后用短线标记; -
showmedians:是否显示中位数(布尔值,默认 False),显示后用短线标记; -
quantiles:用于显示分位数(默认 None),需传入列表或数组指定分位数值(如 [0.25, 0.75] 显示四分位数)。显示后会在小提琴图中以水平线标记指定分位数;
-
points:计算核密度估计时的采样点数(默认值为 100)。数值越大,小提琴轮廓越平滑,但计算量也越大;
-
bw_method:用于计算核密度估计的带宽(控制曲线平滑程度),默认值为 None(自动计算)。可选值可以是数值(直接指定带宽,如 0.5)。字符串(使用经典带宽估计方法,如 'scott' 或 'silverman');
-
side:控制小提琴图的显示方向。可选值:'left'(仅显示左侧)、'right'(仅显示右侧)、'both'(双侧对称,默认值)。3.9版本新增参数;
-
data:用于数据映射的对象。
通过调整这些参数,可以灵活控制小提琴图的视觉效果。
# 生成模拟数据(3组不同分布的数据)
np.random.seed(42)
data = [
np.random.normal(loc=0, scale=1, size=1000), # 正态分布(均值0,标准差1)
np.random.lognormal(mean=0, sigma=0.5, size=1000), # 对数正态分布
np.random.exponential(scale=2, size=1000) # 指数分布(scale=1/λ)
]
plt.figure(figsize=(10, 6), dpi=100)
# 绘制基础小提琴图
violin_parts = plt.violinplot(
data, # 输入数据(3组数据的列表)
positions=[1, 2, 3], # 指定小提琴图在x轴上的位置(分别对应1、2、3坐标)
vert=True, # 垂直方向显示小提琴图
widths=0.8, # 小提琴图的宽度
showmeans=False, # 不显示均值标记
showextrema=True, # 显示极值(最大值和最小值,以短线标记)
showmedians=False, # 不显示中位数
# 为每组数据指定显示的分位数(第一组:25%和75%分位;第二组:10%和90%分位;第三组:20%和80%分位)
quantiles=[[0.25, 0.75], [0.1, 0.9], [0.2, 0.8]],
points=200, # 核密度估计的采样点数
bw_method='scott', # 带宽计算方法('scott'为经典方法,控制曲线平滑程度)
)
plt.xlabel('数据组别', fontsize=12)
plt.ylabel('数值分布', fontsize=12)
plt.title('基础小提琴图示例', fontsize=14, pad=20)
# 设置x轴刻度标签(默认是1、2、3,替换为更易理解的名称)
plt.xticks(ticks=[1, 2, 3], labels=['正态分布', '对数正态分布', '指数分布'])
plt.grid(axis='y', alpha=0.3, linestyle='--')
plt.show()
可视化结果如下图所示:
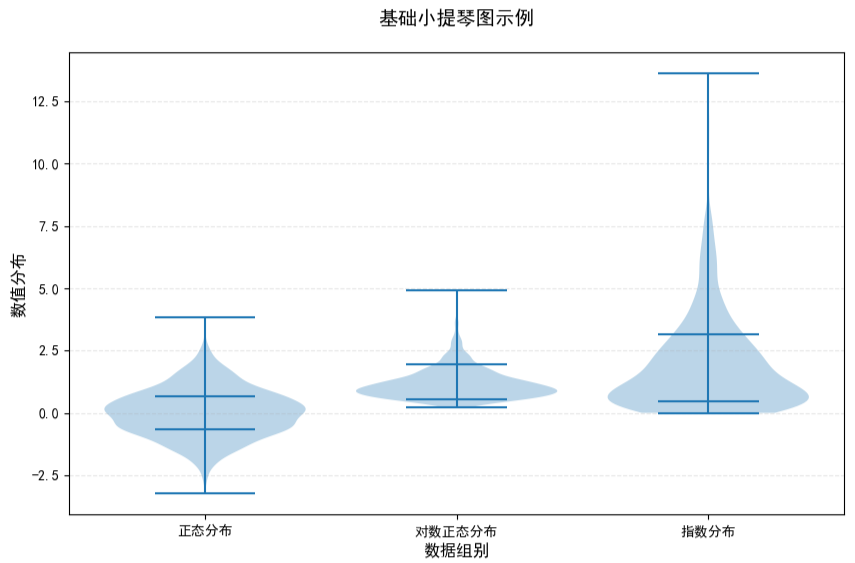
使用示例:
-
示例 1:对比箱线图与小提琴图
-
对称的核密度曲线,展示数据在各个数值区间的概率密度(曲线越宽,该区间数据越多); -
中间线条类似箱线图的统计标记,通常包含中位数(白色点)、四分位数(黑色短线); -
整体形态像一把 “小提琴”,直观反映数据的分布特征(如是否对称、是否有多个峰值)。
import seaborn as sns
# 使用 Seaborn 加载示例数据
tips = sns.load_dataset("tips")
# 创建子图
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 箱线图
axes[0].boxplot([tips[tips['sex'] == 'Male']['total_bill'],
tips[tips['sex'] == 'Female']['total_bill']],
labels=['Male', 'Female'])
axes[0].set_title('Box Plot')
# 小提琴图
axes[1].violinplot([tips[tips['sex'] == 'Male']['total_bill'],
tips[tips['sex'] == 'Female']['total_bill']],
positions=[1, 2])
axes[1].set_xticks([1, 2])
axes[1].set_xticklabels(['Male', 'Female'])
axes[1].set_title('Violin Plot')
plt.tight_layout()
plt.show()
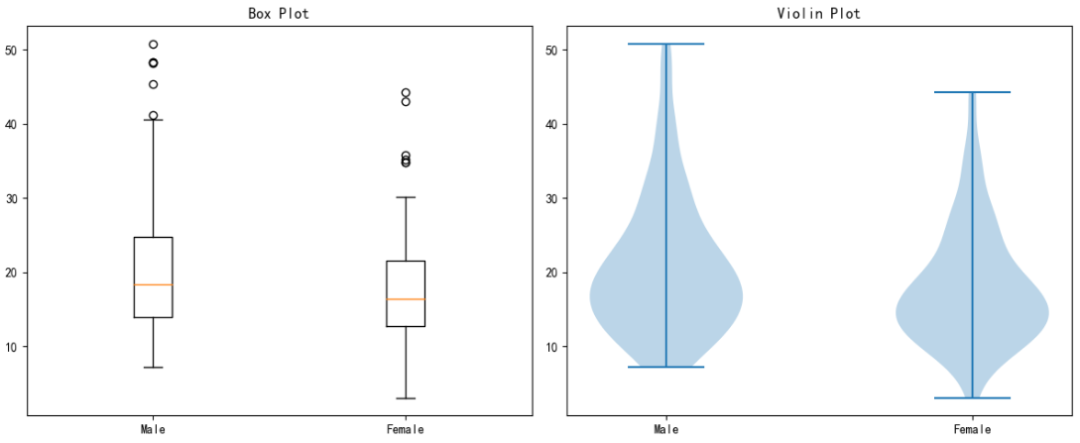
-
示例2:通过返回值自定义样式
violinplot() 函数会返回一个字典,其中包含了构成小提琴图的各种图形元素。字典包含以下键:
-
bodies:包含每个小提琴填充区域的 PolyCollection(多边形集合)实例列表。 -
cmeans:标记每个小提琴分布均值的 LineCollection(线条集合)实例。 -
cmins:标记每个小提琴分布最小值(底部)的 LineCollection 实例。 -
cmaxes:标记每个小提琴分布最大值(顶部)的 LineCollection 实例。 -
cbars:标记每个小提琴分布中心位置的 LineCollection 实例。 -
cmedians:标记每个小提琴分布中位数的 LineCollection 实例。 -
cquantiles:为识别每个小提琴分布分位数而创建的 LineCollection 实例。
后续可以利用这些返回对象来修改小提琴图的样式。
import pandas as pd
# 生成模拟数据:模拟电商平台不同品类商品的用户评分(1-5分)
np.random.seed(42)
df = pd.DataFrame({
'电子产品': np.random.normal(loc=3.8, scale=0.6, size=1000).clip(1, 5), # 均值3.8,限制1-5分
'服装': np.random.normal(loc=4.2, scale=0.4, size=1000).clip(1, 5), # 均值4.2,更集中
'食品': np.random.normal(loc=3.5, scale=0.8, size=1000).clip(1, 5) # 均值3.5,更分散
})
data = [df['电子产品'], df['服装'], df['食品']]
plt.figure(figsize=(10, 6), dpi=100)
# 绘制横向小提琴图,返回包含图表各组件的字典
violin_parts = plt.violinplot(
data,
vert=False, # 横向显示
showmeans=True,
showmedians=True,
showextrema=True,
positions=[1, 2, 3],
widths=0.6
)
# =============美化设置:自定义小提琴图的视觉样式====================
# 设置每个小提琴的填充色与边框样式
colors = ['#FFB6C1', '#FFD700', '#FFA07A'] # 浅粉、金色、浅橙
# 遍历每个小提琴的填充区域(bodies为PolyCollection实例列表)
for i, pc in enumerate(violin_parts['bodies']):
pc.set_facecolor(colors[i])
pc.set_alpha(0.8)
pc.set_edgecolor('darkred')
pc.set_linewidth(0.8)
# 自定义均值线、中位数线、极值线的样式
violin_parts['cmeans'].set_color('blue') # 设置均值线颜色
violin_parts['cmeans'].set_linewidth(4) # 设置均值线宽度
violin_parts['cmedians'].set_color('yellow') # 设置中位数线颜色
violin_parts['cmedians'].set_linewidth(2) # 设置中位数线宽度
violin_parts['cbars'].set_color('red') # 设置中线(分布中心)颜色
violin_parts['cmins'].set_color('purple') # 设置最小值线颜色
violin_parts['cmaxes'].set_color('blue') # 设置最大值线颜色
# 添加中位数数值标签
medians = [np.median(group) for group in data]
for i, median in enumerate(medians):
plt.text(
median + 0.05, # 文字x坐标(中位数右侧0.05)
i + 1.1, # 文字y坐标(对应品类位置)
f'中位数: {median:.2f}', # 文字内容(保留2位小数)
fontsize=10,
color='black',
va='center'# 垂直居中对齐
)
# 添加结论标注
plt.annotate(
'服装品类评分最高n且分布最集中', # 标注内容
xy=(4.2, 2), # 箭头指向的位置(服装品类的均值附近)
xytext=(4.5, 1.5), # 文字位置
arrowprops=dict(arrowstyle='->', color='red', lw=2), # 箭头样式
fontsize=11,
color='red',
fontweight='bold',
bbox=dict(boxstyle='round,pad=0.5', facecolor='yellow', alpha=0.5) # 文字背景框
)
plt.ylabel('商品品类', fontsize=12, fontweight='bold')
plt.xlabel('用户评分(1-5分)', fontsize=12, fontweight='bold')
plt.title('电商平台不同品类商品用户评分分布对比', fontsize=14, fontweight='bold', pad=20)
plt.yticks(ticks=[1, 2, 3], labels=['电子产品', '服装', '食品'], fontsize=11)
plt.xlim(0.5, 5.5) # 调整x轴范围,避免标注被截断
plt.grid(axis='x', alpha=0.2, linestyle='-')
plt.show()
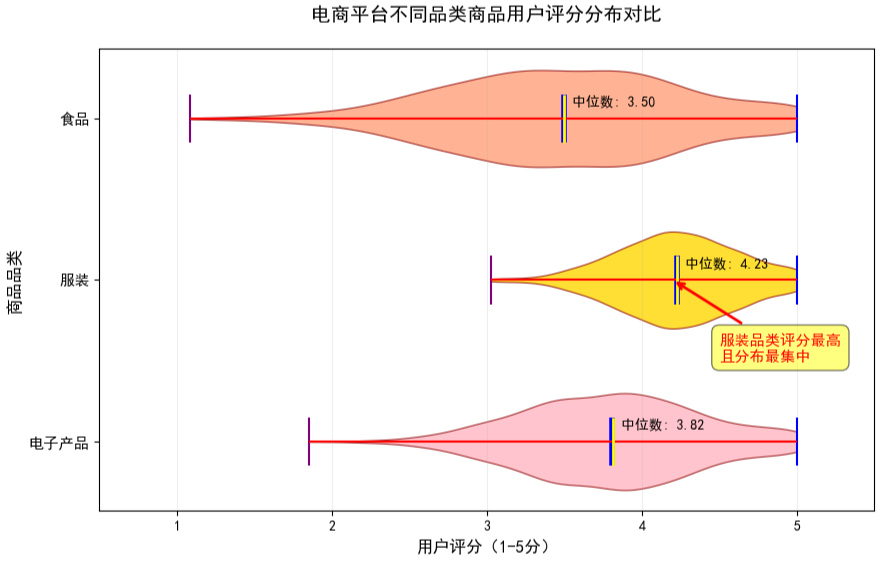
更多内容可以前往官网查看:
https://matplotlib.org/stable/


本篇文章来源于微信公众号: 码农设计师
{kind=link}