本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorch丢弃法:
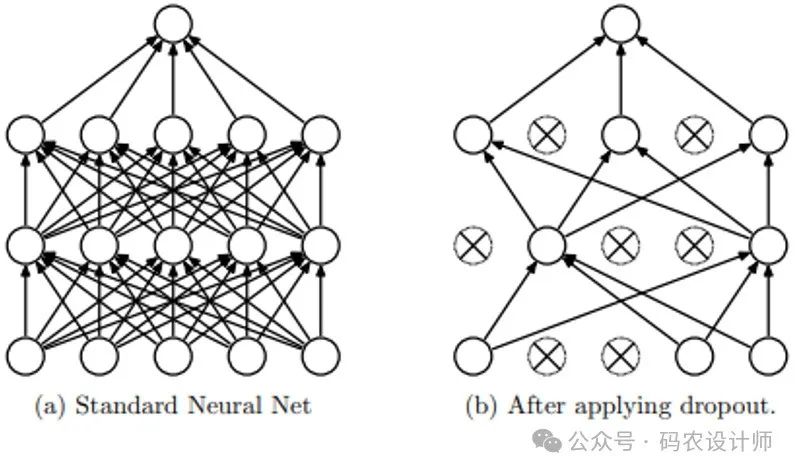
Dropout层:
class torch.nn.Dropout(p=0.5, inplace=False)
其中:
-
p (float, optional): dropout 的概率,即随机将输入单元设置为 0 的概率。默认值为 0.5。这个值必须在 0 到 1 之间(包含 0,但不包含 1),表示在训练过程中每个元素被保留(不被设置为 0)的概率是 1 - p。
-
inplace (bool, optional): 如果设置为 True,将会在原地修改输入数据,而不会创建新的 Tensor。这有助于节省内存,但需要小心使用,因为它会改变原始输入 Tensor。如果设置为 False(默认值),则不会修改原始输入,而是返回一个新的 Tensor。
首先生成了一个随机的张量 data,其中的元素是从标准正态分布(均值为0,标准差为1)。
# 生成了一个随机的张量
data = torch.randn(3,5)
data
# 输出结果:
# tensor([[-0.0663, -0.4402, -0.1610, -1.9872, 0.8562],
# [ 0.1422, 0.3391, -0.3236, 0.6410, -0.4595],
[ 0.2002, -0.2750, -0.3412, 1.5613, 0.6355]])
然后,创建一个 dropout 层,设置 dropout 概率为 0.5。这意味着在应用这个层时,data 张量中的每个元素都有 50% 的概率被设置为 0。将 dropout 层应用到 data 张量上。在这个过程中,data 张量中的大约一半元素会被随机设置为 0。
# 每个元素以0.5的概率随机舍弃
dropout = nn.Dropout(0.5)
# 将 dropout 层应用到 data 张量上
out = dropout(data)
由于 dropout 层不会改变输入张量的形状,所以 out.shape 的结果和 data 的形状一样,即 (3, 5)。
通过输出结果可以看到,结果张量中有些元素被设置为0了。
# 输出结果的形状大小
out.shape
# 输出结果:torch.Size([3, 5])
# 输出结果
out
# 输出结果:tensor([[-0.1326, -0.0000, -0.3220, -3.9744, 0.0000],
# [ 0.0000, 0.0000, -0.6472, 0.0000, -0.0000],
[ 0.4004, -0.0000, -0.0000, 0.0000, 1.2709]])
更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}